-
一、前言
今天这篇文章可能会有点长,涉及到的知识点比较基础但很重要。
写这篇文章的起因是今天工作和另外一个部门的同事联调时,发现他们传过来的 base64编码 后的字符串,我用反base64解不开,最后发现是因为他们做了 base64URL。
今天下班回到家想起这件事,又想起工作近2年接触到了很多很不起眼但又很重要的关键词知识点,觉得可以整理一下,复习下也做个备忘。

二、ASCII、GBK、Unicode、Utf-8编码区别
1. 文本编码的诞生背景
计算机只能处理数字,如果要处理文本文件就必须先把文本转化成数字才能处理。最早的计算机在设计的时候采用8个比特(bit)作为一个字节(byte)。所以一个字节能表示的最大整数就是255 ((2^8) - 1 )。
2. ASCII编码
最早的计算机字符编码为ASCII(美国信息互换标准代码),只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,用一个字节(8个位)就能表示所有的字符。比如大写字母A的编码是65,小写字母z的编码是122。
3. 和汉字相关的编码规范:GB2312、GBK、GB13080
(1)GB2312编码
但是在中国由于汉字数目众多,用一个字节根本表示不了,ASCII就行不通了。因此就有了GB2312(中国国家标准简体中文字符集)。GB2312使用两个字节来对字符进行编码,其中前面的一个字节从0xA1用到0xF7,后面一个字节从0xA1到0xFE。GB2312能表示几千个汉字,并且兼容ASSCII码。
(2)GBK
但后来发现,GB2312还是不够用,于是进行了扩展,产生GBK(汉字内码扩展规范)。GBK同GB2312一样用两个字节表示一个字符,但区别在于放宽了对于低字节的要求,因此也就能表示更多的汉字。
(3)GB13080
后来为了容纳少数民族以及其他其他国家的文字,又出现了DB13080。DB13080兼容GBK与GB2312。与GBK、GB2312不同的是,GB18030采用单字节、双字节和四字节三种方式的字符编码,能容纳更多的字符。
4. Unicode
但是全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc_kr里。各国有各国的标准,就会不可避免的出现冲突。结果就是在多语言混合的文本中,显示出来会有乱码。
这个时候ISO(国际标准化组织)发明了UCS,即Unicode。Unicode把所有语言都统一到一套编码里,这样就不会出现乱码的问题了。
Unicode标准最常用的是用两个字节表示一个字符(如果是非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。但是如果所有的字符都是用Unicode来编码,那对于全英文的文本编码就十分不划算(明明只需要一个字节就够了)。
因此为了节约存储空间和便于传输,就将Unicode编码转化为 “可变长编码”的UTF-8编码,可以理解 Unicode 推动了 UTF-8 编码的诞生。
5. UTF
UTF是Unicode Transformation Format的缩写,意思是“Unicode转换格式”,后面的数字表明至少使用多少个比特位来存储字符。
UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
Tips:不同语言文本打开出现乱码的原因:用A方式将文本编码成二进制,然后用B方式解码,就会乱码。
为什么一个英文字母占一个字节,一个中文汉子占两个字节?
一般计算机字符编码都是采用的ASCII码,它的范围只有0-127,后经扩展也只达到0-255的范围,对于用字母表示的英文,这个范围已经足够了(表示26个字母和数字等已绰绰有余).
可是对于如汉字,日文,韩文等由字形组成的文字,这样的范围就太小了,所以一个汉字都是采用2个字节来表示,并且2个字节开头的一个字节最高位为1(目的是为了区分1个汉字与2个字母),这样编码范围就大增加了.
三、Bit、Byte和网速
1. Bit 和 Byte
Bit 其实就是指 0 或者 1,Byte 是对 8个 Bit 的打包称呼。
电脑是以二进制存储以及发送接收数据的。二进制的一位,就叫做 1 bit。也就是说 bit 的含义就是二进制数中的一个数位,即 “0” 或者 “1”。
字节 Byte 和比特 bit 的换算关系是 1 Byte = 8 bit 。
2. 网速
网速有「宽带大小」和「下载速度大小」
(1)宽带大小(bit)
网络线路的计量单位,也就是我们通常说的 2M 宽带,10 M 宽带的单位,是 比特每秒(bits per second)。比特每秒 的缩写为 bps,意思是每秒接收的平均比特数。更大的单位是 千比特每秒(Kbps)或 兆比特每秒(Mbps)。2M宽带,意味着每秒平均可以接受 2Mb 的数据,也就是二百万左右比特的数据,在这里,小写 b 的意思就是比特了。
(2)下载速度(byte)
而通常我们说的下载速度,也就是网速,是每秒下载的字节数。比如网速是 5 KB(这网速可是够慢的),意思就是每秒接收的数据是 五千字节。
两者关系
那我们根据 一字节 等于 8 比特的 换算方法,就可以得出以下结论。
下载速度从理论上来说,应该是 带宽的 八分之一。
2M 宽带理论下载速度是 256 KB
10M 宽带理论下载速度是 1280 KB
1 | 带宽的单位,不管是 B 还是 b,代表的都是 比特 bit 。 |
四、Base64、Base64URL的关系
1. base64的作用/什么时候需要base64
当你需要用字符串来代替二进制数据的时候,可以考虑base64。
Base64是一种用64个字符来表示任意二进制数据的方法。
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法,那么Base64是一种最常见的二进制编码方法。
2. base64 介绍和应用
Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法。由于 2^6=64,所以每 6 个比特为一个单元,对应某个可打印字符。3 个字节有 24 个比特,对应于 4 个 Base64 单元,即 3 个字节可由 4 个可打印字符来表示。
它不是一种加解密技术,是一种简单的编解码技术。
Base64 常用于表示、传输、存储二进制数据,也可以用于将一些含有特殊字符的文本内容编码,以便传输。
比如:
在电子邮件的传输中,Base64 可以用来将 binary 的字节序列,比如附件,编码成 ASCII 字节序列;
将一些体积不大的图片 Base64 编码后,直接内嵌到网页源码里;
将要传递给 HTTP 请求的参数做简单的转换,降低肉眼可读性;
注:用于 URL 的 Base64 非标准 Base64,是一种变种。
网友们在论坛等公开场合习惯将邮箱地址 Base64 后再发出来,防止被爬虫抓取后发送垃圾邮件。
(1)使用 base64 对图片进行编码
编码流程: 先对图片进行 utf-8 编码 生成 二进制,然后 base64 再对 二进制进行编码,生成 base64 字符串
解码流程: 先对 base64字符串 解码 生成 二进制,然后使用 utf-8 解码生成图片
(2)有了utf-8编码,为什么还需要base64?
试想一个场景,你用 utf-8 把文件编码成二进制后,你交给别人,别人知道应该用 utf-8 进行解码吗?
基本不会知道的,但如果你用了 base64 ,稍微熟悉点开发的同学都知道这是 base64 编码的,再对应 decode 就好了。
相当于 base64 给 二进制 附加了解码的信息。
3. base64 编码原理
标准 Base64 里的 64 个可打印字符是 A-Za-z0-9+/,分别依次对应索引值 0-63。索引表如下:
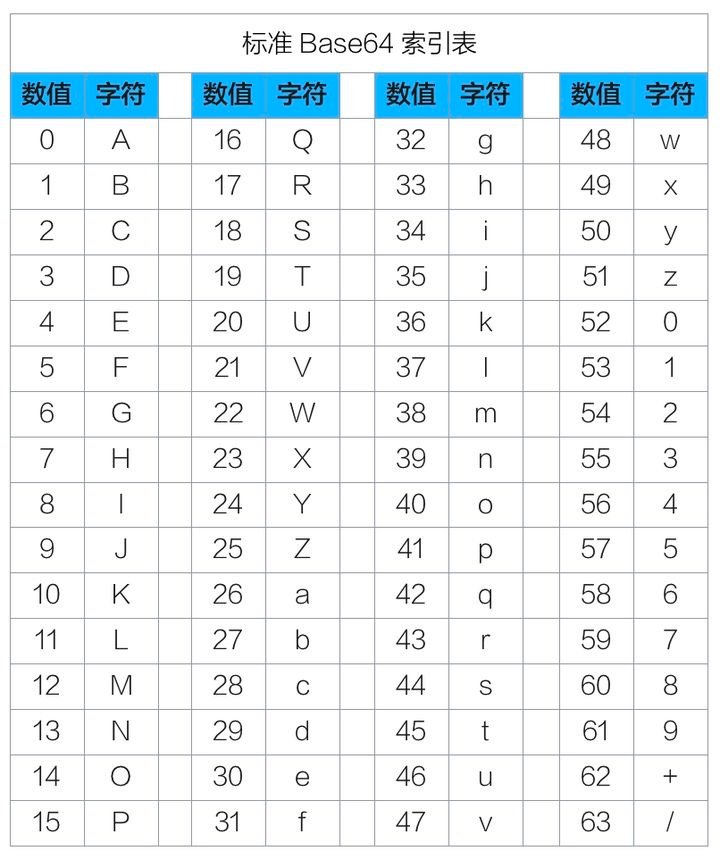
编码时,每 3 个字节一组,共 8bit*3=24bit,划分成 4 组,即每 6bit 代表一个编码后的索引值,划分如下图所示:

这样可能不太直观,举个例子就容易理解了。比如我们对 cat 进行编码:
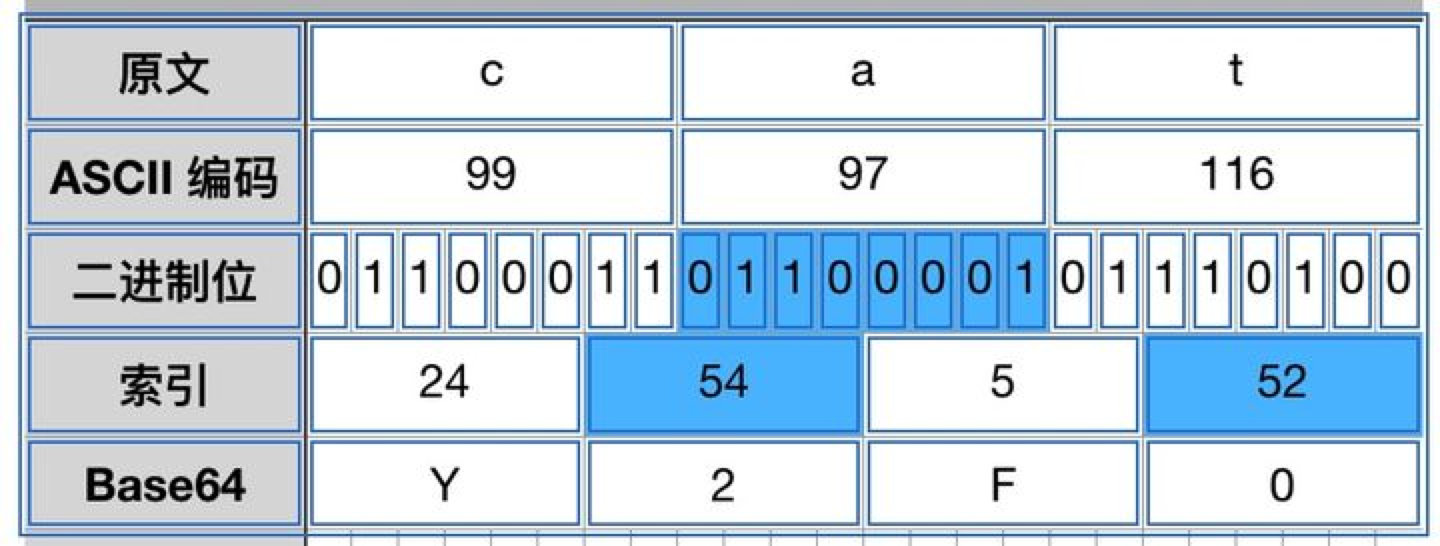
可以看到 cat 编码后变成了 Y2F0。
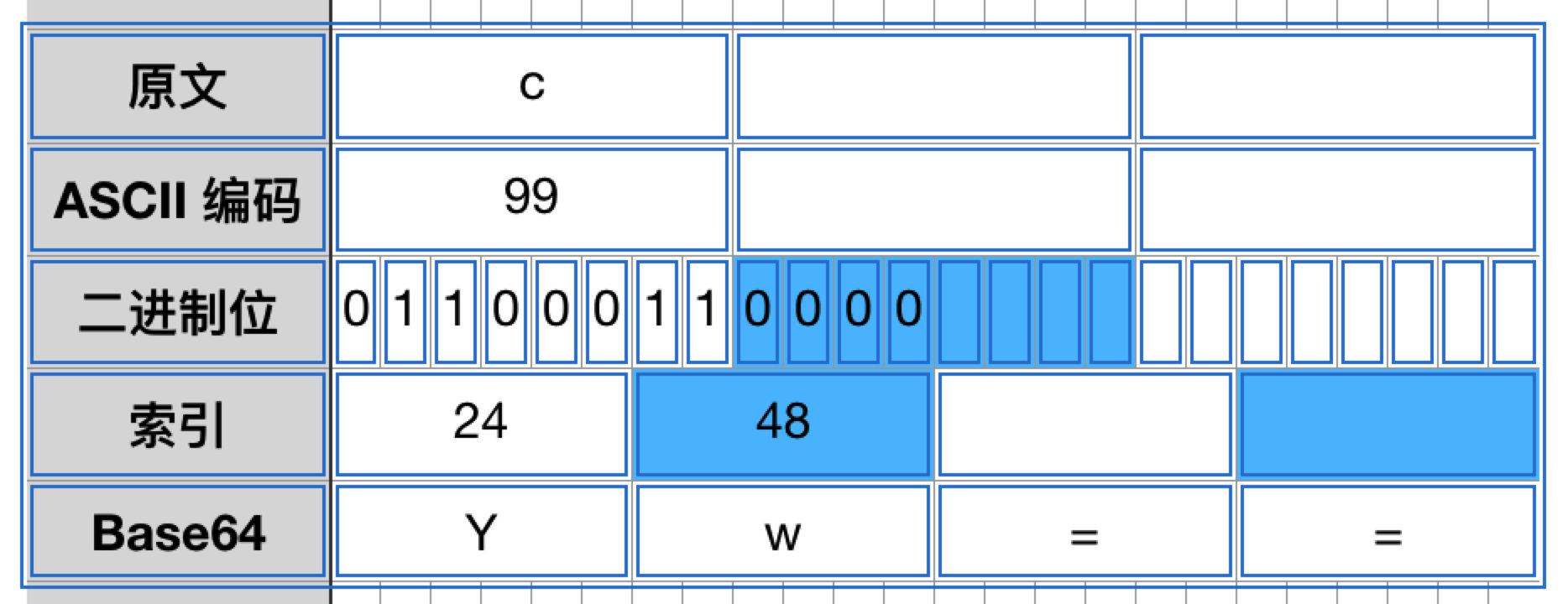
如果待编码内容的字节数不是 3 的整数倍,那需要进行一些额外的处理。
如果最后剩下 1 个字节,那么将补 4 个 0 位,编码成 2 个 Base64 字符,然后补两个 =:
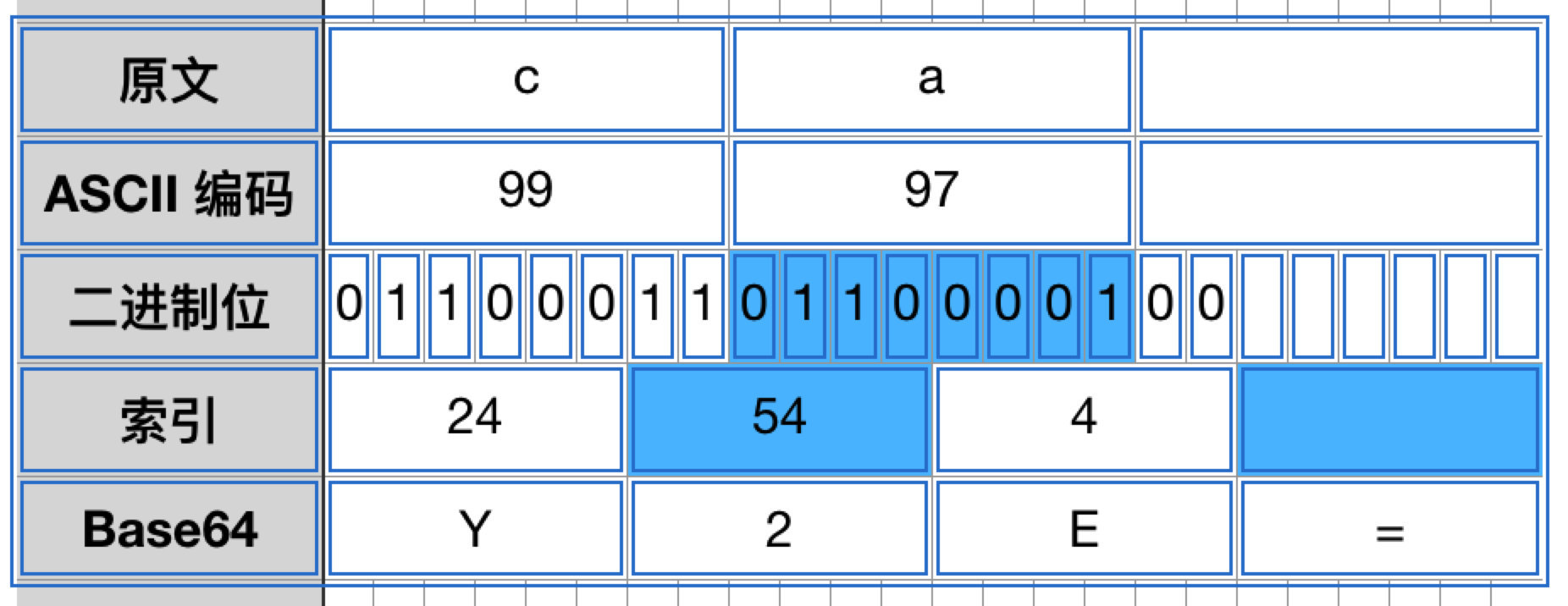
如果最后剩下 2 个字节,那么将补 2 个 0 位,编码成 3 个 Base64 字符,然后补一个 =:
4. base64URL 是什么?
BASE64URL是一种在BASE64的基础上编码形成新的加密方式,为了编码能在网络中安全顺畅传输,需要对BASE64进行的编码做处理,特别是互联网中。
BASE64URL编码的流程:
1 | 1、明文使用BASE64进行加密 |
BASE64URL解码的流程:
1 | 1、把BASE64URL的编码做如下解码: |
5. 兼容 base64Url 的安全的解码方法
1 | // base64 url 解码 |
顺便也贴一份 iOS base64Url 的编码方法
1 | // base64 url 编码 |