-
问题
什么是进程?什么是线程?
为什么有的设计是支持多线程的(OC)?有的设计却是单线程的(JSCore)?
操作系统的 I/O 和 文件管理 是怎么做的?
CPU 多核是不是分时系统就可以做得更快了?
为什么OC开发调用渲染相关,不在主线程就会crash?
进程和端口有什么关系和区别?
tableView 涉及UI刷新和数据源操作的 多线程crash问题,是怎么解决的?
多线程和锁如何结合使用?
iPhone 微机结构是怎么样的?地址总线是多少,单进程内存上限是多少,某个 App 内存过大会怎么做?
蓝牙没有通过硬件线连接,是怎么实现字符数据传输的?
磁盘和内存条有什么区别?
《操作系统设计与实现》
第1章 引言
MINIX 3 (可以称为: mini - Unix)的系统调用大致可以分为两类:
- 与进程有关的系统调用
- 与文件系统有关的系统调用
1.3.1 进程(process)
- 什么是进程?
进程的本质就是一组内存地址而已,在内存地址上会运行程序。
- 分时系统的工作原理
因为 CPU 是不能处理并发问题的,任何单CPU计算机一次只能执行一条指令,所以需要用分时系统来分配CPU资源。比如,给每个进程分配1秒的时间片,运行完之后就挂起进程,等待下一次恢复进程。
- 进程表 process table
当进程被挂起再恢复,需要保证恢复时的状态和挂起的状态完全一致,这时就需要 进程表(process table)来记录进程被挂起的状态。
- 进程创建于销毁
一个进程可以创建一个或多个其它的进程(称为子进程),而且这些子进程又可以创建它们自己的子进程,这样就生成了一棵进程树。
- 进程的通信
有时一组相关的进程需要相互合作,共同完成某项任务,所以它们就要相互通信以协调各自的进展。
- 进程有关的其它系统调用
- 请求更多内存 或 释放无用内存
- 等待子进程结束
- 加载并执行另一个进程
1.4 系统调用


Tips:
上面两张表格非常有意思,首先可以明白,操作系统主要在处理四大部分:
- 进程管理
- I/O设备管理
- 存储管理
- 文件管理
然后还能看到一些神奇的方法,比如 ‘时间管理’ 中有 ‘设置文件上次访问时间’ 的能力,既然操作系统都提供这种能力,那么应用层肯定也是可以拥有这种能力的。
1.4.1 进程管理的系统调用
- 创建进程的唯一方式:fork
创建进程的方式很有意思,是直接在 parent 的进程 fork 出一个子进程,除了内存地址和PID(标识号)不一样,里面的内容(文件描述符、寄存器的值等)都是一样的。
- 等待子进程执行完毕
父进程创建子进程后,可以使用 waitpid 等待某个特定子进程执行完毕。
- 代码段(text segment,即程序代码)、数据段(data segment,即变量)和栈段(stack segment)
注意了,代码段、数据段、栈段,在操作系统里也有相应的分配,它的含义和微机是一样的。
1.4.2 信号管理的系统调用
信号可以理解为通知进程做事的信号
1.4.3 文件管理的系统调用
read 和 write ,没有太值得说的内容,略。
1.5.1 整体结构
操作系统其实没有什么”结构”可言,它就是一组函数的集合。
Tips:醍醐灌顶
当然了,说操作系统很整体化,但在某些地方还是存在结构化的,比如在执行指令时,可以选择是以 用户态角色 执行,还是以 内核态角色 执行。
- 内核态:供操作系统使用,在该状态下可以执行所有的指令
- 用户态:供用户使用,在该状态下不能执行 I/O 操作 和 其它一些操作
从实现上,可以使用如下的一种结构:
- 主程序:用来调用被进程
- 进程提供的方法
- 工具函数
可以用两种观点来看待操作系统:
- 资源管理器:操作系统的任务是高效地管理整个系统的各个部分
- 扩展机:为用户提供一台比物理计算机更易于使用的虚拟计算机
第2章 进程
2.1 进程介绍
我们都知道,CPU是不能并发处理任务的,但我们平时使用电脑:既可以放歌,又可以读取磁盘,同时我们也可以打字聊天。仿佛这些事情都是在并发发生的,实际上这是一种 伪并行。
只是因为在1s期间,运行了多道程序。
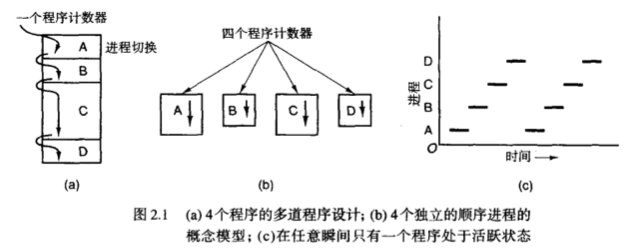
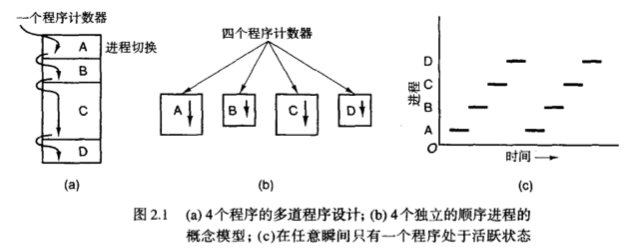
每个进程都是拥有自己的内存地址,从概念上说每个进程都拥有它自己的虚拟CPU。但实际上CPu是在各个进程之间来回切换,进程是 顺序进程。
2.1.1 进程模型(顺序进程)
进程时间分片的处理示意图:

2.1.5 进程的状态
进程有在三种状态中切换:
- 运行态:在该时刻实际占用处理机
- 就绪态:可运行,因为其它进程正在运行而暂时被挂起
- 阻塞态:除非某种外部事件发生,否则不能运行
2.1.6 进程的实现
为了实现进程模型,操作系统维持着一张表格(一个结构数组),即 进程表(process table)。
操作系统是如何在「单个CPU、多个I/O设备」的计算机维持 并发进程 的假象呢?(这是操作系统的最大优势所在)
使用 中断向量表 完成进程的切换,进程实际上是操作系统层面的事情,CPU只关心操作指令。
2.1.7 线程
什么场景下需要线程呢?
比如在网络浏览器的背景下,有100个小图片要下载,因为下载的时间等于「网络连接+网络下载」之和,而下载小图片最耗时是在「网络连接」阶段,如果是单线程,一个下载成功再开启下一个任务,体验就非常糟糕。
我们观察进程,进程有单独的内存地址,内存就是资源,但如果内存中只有一个 控制流,某些情况下就不满足情况。
也即有些情况需要在相同的地址空间中有多个 控制流 并行运行,就好像它们是单独的进程一样(只是它们共享相同的地址空间),这些控制流通常被称为 线程(thread),也可以叫做 轻量进程。
进程类似App的所有内存资源,而线程就是合理分配这些内存资源的一种手段。
当然了,当你的进程里开启了多线程,那需要得不再是 进程表 ,而是 线程表。线程也会变得像进程一样,可处于 运行态、就绪态和阻塞态。
那么线程的操作是放在内核态还是用户态的呢? 有的CPU是放在内核态,有的则是放在用户态。
2.2 进程间通信
进程间需要通信,这点我们是非常清楚的,在详解进程间通信前,我们先逻辑进程间通信的类型:
- case I :一个进程向另外一个进程传送信息
- case II : 保证两个或多个进程在涉及临界活动时不会彼此影响(比如两个进程都试图压榨最后100KB内存的情况)
- case III : 进程存在依赖关系时,要确认好顺序(进程A产生数据,进程B打印数据)
Tips:当然了,我们清楚:线程被称为 轻量进程 ,所以上面三种case和以下要介绍的处理方案,也使用于线程。
2.2.1 竞争条件
这里说的”竞争条件”也就是我们平时开发时经常说的:多线程读写问题。
这里我们描述一个场景:
背景:
- 进程A和进程B有一段共享内存。
- in:指向目录中下一个空闲的槽
- out:指明下一个被打印的文件
- 进程A:打印文件目录管理进程
- 进程B:打印文件进程
流程:
- 进程A读到in为7,存到局部变量 next_free_slot中,发生时钟中断,切换CPU
- 进程B读取in为7,于是将要打印的文件存入7,并将in更新为8,继续其它操作
- 进程A恢复,因为上次读取到的in为7,所以A就把自己要存的文件直接存到7,也就把进程B存的文件给覆盖掉了
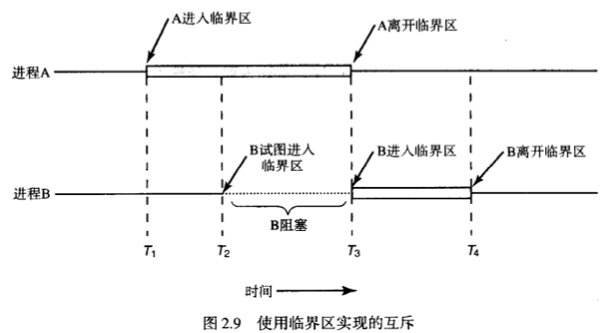
2.2.2 临界区
什么是临界区?
这里把 对共享内存进行访问的程序片段 称为 临界区 或 临界段。
如果能够进行适当的安排,使得两个进程不可能同时处于临界区,则能够避免竞争条件。
Tips:也就是要对进程做互斥,像下面这种样式:

2.2.3 忙等待形式的互斥
2.2.2 说了临界区互斥的想法,那可以用哪些方法来实现临界区互斥逻辑呢?
1. 关闭中断
出问题的原因是因为 时钟中断 会让CPU走时间分片的逻辑切进程,那我让进入临界区的进程把 中断 给关了,离开之前再恢复中断,就实现目标了。
不过这个设计风险非常大,关中断的权利不应该交给用户进程,不然有个进程写出了bug,没有在离开临界区恢复中断,那整个系统都崩了。
2. 锁变量
提到进程互斥、多线程安全,大家脑海中第一时间想到的可能就是 加锁。
比如:设置一个 共享变量,初值为0,当一个进程想进入临界区,就把共享变量设为1,如果共享变量已经为1,就表示已经有进程在临界区了,就阻塞。
实际上这个想法也会有问题,比如这个路径:
- 进程A读取共享变量(if),在将共享变量设为1之前(set),时钟中断切CPU分片
- 进程B读取共享变量,把共享变量设置为1,进入临界区
- 进程A恢复,把共享变量设置为1,进入临界区。
3. 严格交替法
严格交替法的理念虽然好,但不通用,而且会产生 忙等待(busy waiting)的情况。
什么是 忙等待 ?
就是你在 waiting 的过程中,还非常 busy(做大量计算,判断是否轮到自己了)。
流程是:
整形变量 turn 用于跟踪轮到哪个进程进入临界区,类似 switch case 中 传入的 type。
- 进程0检查 turn,发现是0,进入临界区
- 进程1检查 turn ,发现是1,于是等待,直到 turn 变成 1,再继续执行。
这个过程中,进程1一直在执行 while 检测,虽然在等待,但也非常忙碌,这种忙等待,应该是要避免的,因为它会浪费CPU的时间。
只有在有理由预期等待时间很短的时候才使用忙等待(也就是你预期等待不会等很久),比如 自旋锁(spin lock)就采用了忙等待。
Tips:上面说的几个方法思路都是对的,就是进程进入临界区之前先做检查,但这几个方案都出现了忙等待的情况,不够优雅,而且没办法处理进程的优先级问题。
2.2.4 睡眠和唤醒
睡眠和唤醒,对应的是 sleep 和 wakeup,是系统调用进程的方式。
1. 生产者-消费者问题
背景:
- 生产者:进程A,负责向临界区写入数据
- 消费者:进程B,负责向临界区消费数据
如果临界区快满了,生产者还想继续写数据,就会出现问题,这时候应该先把生产者 sleep,让消费者先消费数据。
这个作法听起来简单,既然我们需要一个变量来记录数据,实际操作时也会产生 2.2.1 中描述的问题,所以还是要先解决 2.2.1 的问题。比如这个路径:
- 消费者刚读取 count 发现数据为 0,调度器就决定暂停消费者启动生产者
- 生产者向数据 count + 1 变为1,生产者推断由于 count 刚才为0,消费者一定在睡眠,于是生产者 wakeup 唤醒消费者
- 但消费者此时并未睡眠,所以唤醒信号丢失。消费者下次再运行,发现之前读到的 count 是 0,于是去睡眠。
- 这样的结果是生产者迟早会填满整个缓冲区,然后睡眠,这样一来两个进程都永远睡眠下去。
这个问题的本质在于 生产者 唤醒 消费者 的 wakeup 信号丢失了,这个问题我们可以使用信号量来解决。
2.2.5 信号量
既然之前的方法都解决不了问题,那就再新增中间层呗,所以为了解决上述问题,引入了 信号量 这个概念,信号量 是一个整型变量,用来累计唤醒次数。
- down:对应 sleep,也就是会把 信号量 -1
- up:对应 wakeup,也就是会把 信号量 +1
Tips:不用过于纠结 down 和 up 对应的是 sleep 还是 wakeup,只需要明白 down 和 up 用来达成互斥就好了。
2.3 经典IPC问题
2.3.1 哲学家进餐问题
归类为:多个竞争进程互斥地访问有限资源(如 I/O 设备)

这个问题有三个思考的步骤:
1. 先实现不考虑多进程的代码(能看就行版)

然后这种情况下可能会出现 饥饿 状态,饥饿 指的是:本身是有资源的,但因为程序写得有问题,所有程序又吃不到资源。
饥饿:所有的程序都在运行,却又无法取得进展。
比如这个流程会出现饥饿:
- 某一瞬间,所有的哲学家都同时启动上面的算法,拿起左叉,看到右叉不可用,又得放下左叉
- 过了一会,又同时拿起左叉
2. 无脑加锁的代码(能用就行版)
- 对 think 后的五条语句进行保护
- 拿起叉子前,先对信号量 mutex 执行 down
- 放回叉子后,再对 mutex 执行 up
这个流程会有一个问题,既然我们对 think 后的五条语句加了锁,就表示除了被信号量锁住的进程,其它进程是不允许执行进餐行为的(因为执行前要先判断有没有加锁),同一时间只能有一位哲学家在进餐。
这里额外说一句,学到这里大家应该要清楚:目前我们的加锁并不是让进程的时钟中断禁止执行,而是每个进程执行前会访问一个全局变量(锁)决定是否可以执行代码,也就是会说:加锁时,CPU的时间分片机制还是在运转的,并不是锁定了进程。
3. 优化上锁流程(完美版)

既然5个哲学家公用一把锁会出现「同一时间点只能有一位哲学家在吃饭」,那我们就尝试给每个哲学家加一个信号量来解决这个问题。
2.3.2 读者 - 写者问题
飞机订票系统:多个进程读,一个进程写,如果保证数据一致性?
读者到来而正有一个写者在等待时,则读者被挂在写者后边,而不是立即进入。
2.4 进程调度
多个进程ready,但CPU该调用哪个进程,就需要操作系统中的 调度器(scheduler)来决定,scheduler 使用的就是调度算法。
我们从直观上可以就可以将调度算法分为两个类型:
- 非抢占式调度算法:算法跳转一个进程执行,直到这个进程阻塞或自愿退出,再选择下一个进程
- 抢占式调度算法:每个进程有一个最大允许时间,过了这个时间就把你挂起来,去执行下一个进程。
抢占式调度算法里有一个「最大允许时间」,这个时间是通过 「时钟」来提供的。
在实际的操作系统中,按照实际用途可以分为三个应用类型:
- 批处理系统
- 交互式系统
- 实时系统

Tips:这里有个互斥的指标需要关注一下: 「吞吐量 x 周转时间」,有点类似「召回率 x 精准度」的区别。
2.4.2 批处理系统中的调度
1. 先到先服务
非抢占式先到先服务算法。
2. 最短作业优先

当然了,最短作业优先的算法只有所有作业是同时启动才是最优的,如果作业是不断加进来的,那最短作业优先不一定是好方法了,比如:

3. 最短剩余时间优先
抢占式版本,新的作业进来,和当前运行进程的剩余时间作比较。相当于是动态运行的 最短作业优先 。
4. 三级调度
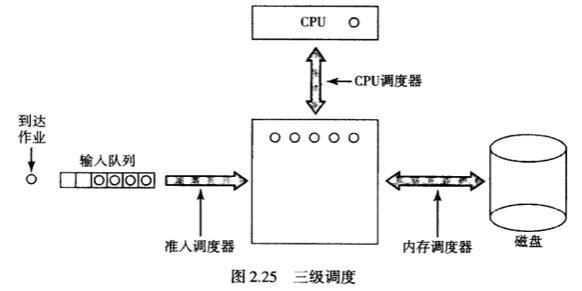
- 准入调度器(第一级):决定哪些作业可以进入系统,被创建进程
- 内存调度器(第二级):决定哪些进程存内存,哪些进程存磁盘
- CPU调度器(第三级):决定如何调度执行已经被创建好的进程(也就是调度算法)
2.4.3 交互式系统中的调度
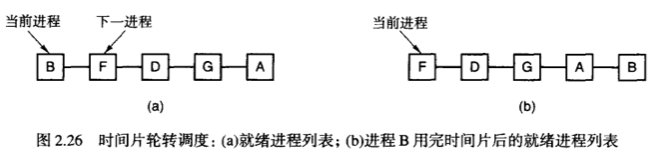
1. 时间片轮转调度
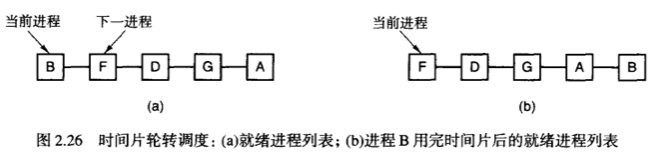
时间片切换这个算法我们很清楚,它算是最古老、最公平的调度算法了,但实际上我们一直担心的一件事:时间片切换时,上下文的切换需要多长时间?
切换进程时,进程需要完成一系列上下文切换的逻辑,包括但不限于:
- 内存映射、清空
- 重新调入告诉缓存
假设时间片设为4ms,上下文切换需要1ms,那CPU 20%的时间都浪费在了管理开销上。
也即:
- 时间片设得太短,会导致过多的进程切换,降低了CPU效率
- 时间片设得太长,引起对紧急交互请求的响应变差。
将时间片设为 20~50ms 通常是一个比较合理的这种方案。
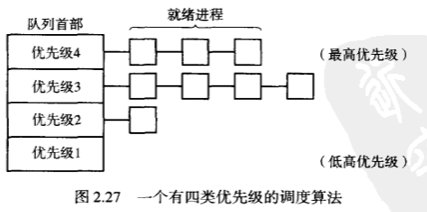
2. 优先级调度
优先级可以静态,也可以是动态变更的。
3. 多重队列
上面我们说过 进程存磁盘 的知识点,我们这里介绍一个实例:
背景:
CTSS 存在进程切换速度太慢的问题,原因是 IBM 7094 内存只能存放一个进程,每次切换都需要将当前进程换出到磁盘,并从磁盘上读入一个新进程。
为了解决 100 个时间分片 的任务需要被切换100次的尴尬事件,CTSS 对进程进行了分类,每一个进程用完时间片后,就提升它下一次可以使用的时间分片。
用100个时间片的任务举例:最初被分到1个时间片,然后被换出,下次可以获得2个时间片,接下来就是 4,8,16,32和64.
4. 最短进程优先
选用 最短作业优先 对于降低 最短平均响应时间 是好的,但现在问题是:如何从当前就绪的进程中找到最短的那一个?
有一种方法是用「a*先前运行的时间 + (1-a)*当前预估」来进行判断。
5. 保证调度算法
向用户明确的性能保证,然后去实现它。
6. 彩票调度算法
对于CPU调度,系统可能每秒抽取50次彩票,每次的中奖者获得20ms的运行时间。
更重要的进程被给予更多的额外彩票,增加中奖机会。
7. 公平分享调度
也就是说:按用户的粒度去划分CPU,而不是按进程的粒度。
2.5 MINIX 3进程概述
2.5.1 MINIX 3 的内部结构

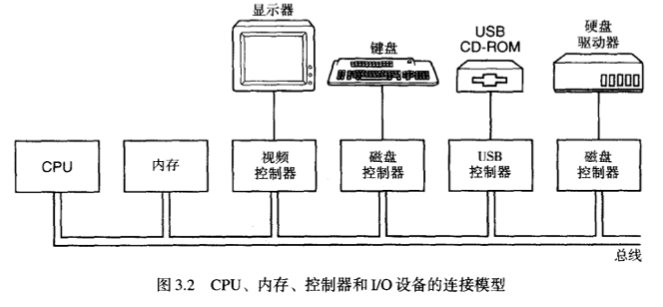
第3章 输入/输出系统
3.1 I/O 硬件原理
3.1.1 I/O 设备
- 块设备:比如磁盘,会将信息存储在固定大小的块中,每个块都有自己的地址。
- 字符设备:比如鼠标、键盘。发送或接收的是字符流,不存在存储和寻址操作。
3.1.2 设备控制器
3.1.2 内存映射I/O
我们将电子部件称为 设备控制器 ,每个控制器中都有一些和CPU通信的寄存器。
CPU可以写入这些寄存器来操作 控制器,比如发送数据、接收数据、开启或关闭。
除了寄存器,还有一些数据缓冲区需要CPU来写入数据,比如 显卡的视频RAM,那么现在问题来了。
CPU 是如何与 RAM这种数据缓冲区 进行通信的呢?
很简单,给 控制器 开一个端口就好了,那么开端口有哪几种方案呢?
给控制器开端口有3种方案:
- 单独的I/O和内存空间
- 内存映射I/O
- 混合方案
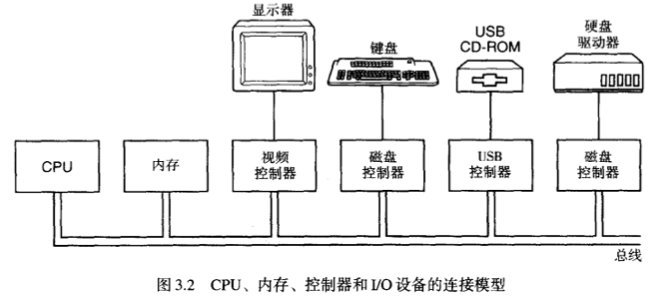
有啥区别呢?
在CPU操作时,需要把相应的地址放到地址线上。
- 如果放上去的地址是I/O空间,I/O设备响应请求。
- 如果是内存空间,内存将响应请求。
3.1.5 直接存储器存取
我们知道,CPU请求数据受到数据总线的限制,对于像磁盘这样能产生大块数据的设备,如果还用传统的总线流程,会浪费CPU的时间。
所以对于 磁盘 的读写,经常采用一种 直接存储器存取(DMA:Direct Memory Access) 的方案。
在介绍DMA之前,我们先看一下没有使用DMA技术,磁盘读操作是怎么放生的:
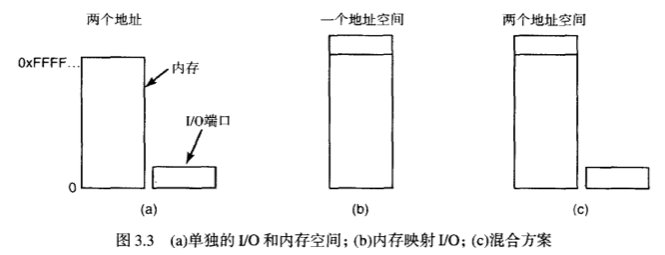
- CPU 循环往复地从 控制器设备读取一个字节或一个字,将其存进内存,增加内存地址,减少要读的数据个数,直到减为零为止
当使用DMA后,流程是如图。
这里大家看图可能会发现一个问题,为什么控制器不直接把磁盘读入的字节存储在主存,而是需要一个内部缓冲区?有两个原因:
- 磁盘控制器能在传送之前校验数据,而不是把脏数据读到内存里
- 磁盘读出的位流是按恒定速度到达的,同时磁盘读出的数据写入内存必须获批地址权限,如果写入过程中阻塞了,地址没有被及时开辟,控制器就需要先把这些磁盘的数据缓存下来。
当然了并不是所有的计算机都使用DMA。如果CPU没有其它工作做,让快速地CPU等待慢速的DMA是没有意义的。
3.2.3 设备驱动程序
很小的时候我们给台式电脑装鼠标,装摄像头,都需要先安装驱动,安装驱动到底是在做什么呢?
而且不同的设备还要安装不同的驱动,这是为什么呢?
首先我们要知道,不同的设备控制器有着不同的寄存器,这些存储器的设计完全不同:
- 比如有的寄存器支持接收命令,有的只是读取状态
- 记录的数据结构也完全不同,比如鼠标需要记录移动了多远,磁盘则必须知道扇区、磁道、柱面、磁头等等。
所以,每个连接到计算机上的 I/O 设备都需要一些设备特定的代码来控制它,这样的代码就称为 设备驱动程序。
计算机 <—> 设备驱动程序 <—> 设备控制器
第4章 存储管理
存储器层次结构:
- 第一层:CPU内部的一些寄存器,访问速度最快,容量不大,价格最贵
- 第二层:高速缓存(cache)
- 第三层:主存储器(内存),访问速度适中,价格也适中。
- 第四层:磁盘,访问速度慢,价格便宜。
前三层都是易失型的,断点后内容会丢失。
存储管理器的三个任务:
- 记录,记录存储器的使用情况,即哪些正在使用,哪些部分还闲着。
- 分配和回收,进程需要空间就分配给它,进程结束再回收回来
- 容灾,内存太小容不下所有进程,就需要把内存中暂时不能运行的进程送到磁盘上,然后再把磁盘上的另一个进程装入内存。
4.1 基本的存储管理
4.1.1 单道程序存储管理(废弃的技术)
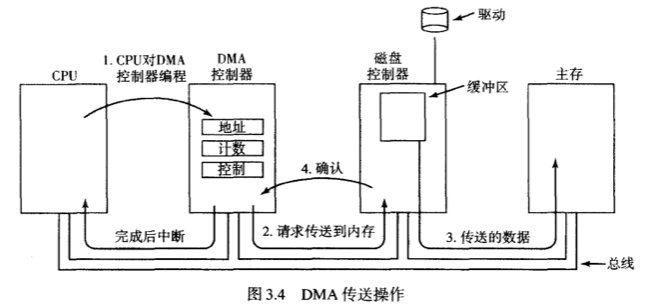
在单道程序存储管理方式下,每一次只能运行一个程序。当用户输入一条命令后,操作系统就把旧的程序覆盖掉,然后从磁盘把数据装入内存并运行之。
这样的内存管理方式现在基本只有一些简单的嵌入式系统在使用了,扩展性太差。
4.1.2 固定分区的多道程序系统(废弃的技术)
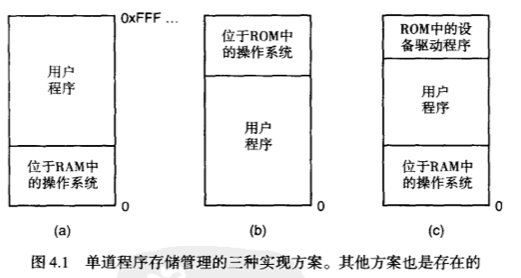
这个方式的基本原则就是 内存被按照某个策略固定分配好了,然后按一些策略把进程塞到内存里。
这种模型现在也很少使用了。
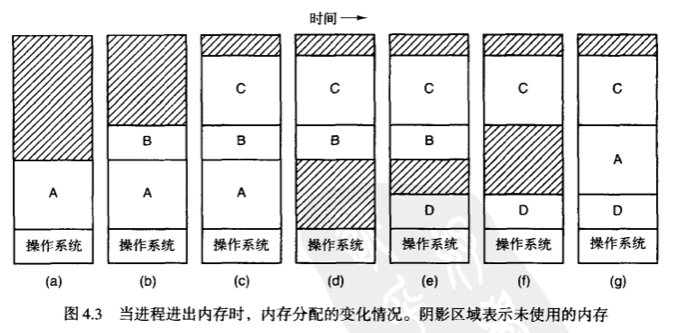
4.2 交换技术
我们都知道内存很有限,那么如何在有限的内存中尽可能多地去运行更多的进程,是一个要研究的技术,这里涉及两种策略:
- 交换技术:将各个进程完成地调入内存,运行一段时间,然后再放回磁盘上
- 虚拟存储器:在这种技术下进程即使只有一部分内容存放在内存中,也能运行(4.3 介绍)
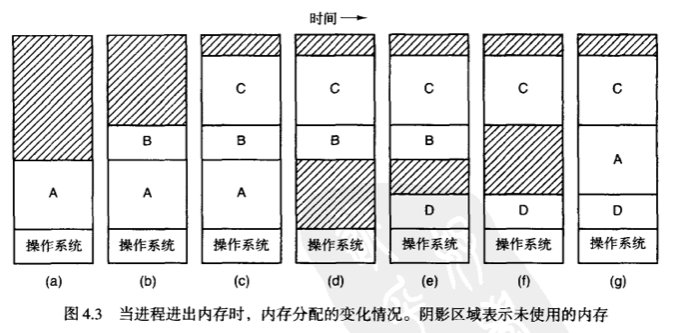
随着进程的换入换出,内存中会有一些不连续的黑洞(即比较小的空闲分区),这时怎么把黑洞部分重新利用起来呢?
可以使用 内存紧缩(memory compaction)技术,也就是说,把所有的进程都尽可能地往内存地址的低端移动。
不过 内存紧缩 技术会耗费大量的 CPU 时间,例如在一个1GB内存、每秒可复制2GB的计算机上,把全部内存紧缩一次需要0.5s。
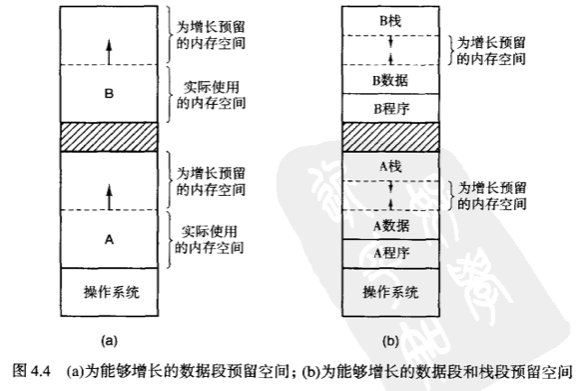
这时我们开始想到 OC 的一个特点,动态的语言,支持动态内存分配,那怎么来让进程的内容增长呢?
- 如果进程邻接一个空洞,那么可以把这个空洞分配给它
- 旁边如果临近的是一个进程,那么要么把自己替换到一个足够大的空闲区中,要么邻接的进程交换出去换取更大的空间,不然就等待或被杀死。
当然了,进程有两个可增长的段,我们也可以提前预留好一部分空间:
- 数据段:用于当做堆空间
- 栈段:用于存放普通的局部变量和返回地址
4.2.1 基于位图的存储管理
Tips:图c说的是 链表存储管理。
位图有它的缺点:当决定把一个大小为k个分配单元的进程调入内存时,内存管理器必须搜索位图以找出一串k个连续的0,这种操作是比较慢的。
4.2.2 基于链表的存储管理
如上 4.2.1 所描述的,H表示空闲区(hole),P表示已被某个进程占用了(process)。
基于链表的存储管理更加通用。
4.3 虚拟存储管理
内存不够怎么办?就用磁盘来凑。
虚拟存储管理的思路是:程序的代码、数据和栈的总大小可以超过实际可用的物理内存大小。
操作系统把当前需要用到的那些部分保留在内存中,而把其余部分保留在磁盘上。
例如:一个大小为512MB的程序,可以运行在一台内存空间只有256MB的机器上。采用的方法就是在进程运行的每个时刻,经过精心挑选,只保留的程序代码和数据在内存中,然后再需要的时候把程序片段在内存和磁盘之间来回交换。
4.3.1 虚拟页式存储管理
虚拟存储管理技术的应用背景和大致流程我们清楚了,但具体怎么实现虚拟内存管理呢?
「虚拟页式存储管理」也就是 分页(paging)技术,是大部分虚拟存储系统采用的方法。
既然我们把 磁盘也当内存来用了 ,那肯定需要一个工具来帮忙我们把磁盘的地址做映射,这个工具就是 存储管理单元(Memory Management Unit,MMU),由它负责把 内存的虚拟地址 映射为 磁盘的物理地址。
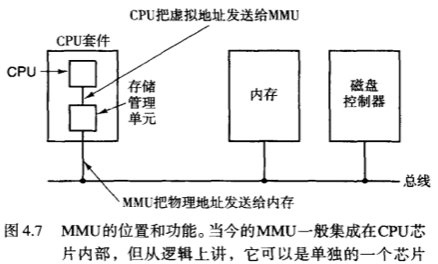
那么虚拟地址和物理地址是如何实现映射的呢?我们举一个例子:
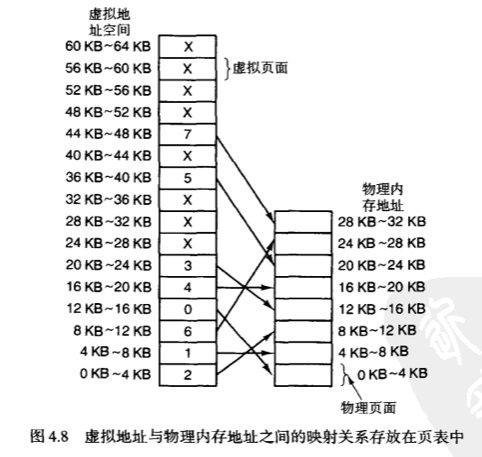
操作流程是:
- 访问虚拟地址时,硬件会有一个 有效位 来描述每个虚拟页面是否在内存中
- 如果访问虚拟地址发现没有相应的内存映射,MMU就会发起一个 缺页中断,把这个问题提交给操作系统去处理
- 操作系统将从内存中选出使用频次不够多的物理页面A,把页面A写回磁盘,然后把引发缺页中断的那个虚拟页面装入该空闲页面A,并对地址映射关系进行更新。
所以大家明白了吗?虚拟内存技术并不是操作系统直接访问磁盘,而是不断更替内存里的内容。更替地逻辑类似LRU算法。