-
本文归属于iOS 动画(从API调用到微机原理),
建议按iOS 动画(从API调用到微机原理)顺序进行阅读。
本文目录:
1 |
|
一、先备知识
(一)位图
涉及到 CALayer 的时候,我们经常会提到 位图(BitMap) ,但涉及大数据存储的时候,我们也会用到 BitMap ,这就很容易让人搞混。
实际上,虽然这两个场景下都是叫 位图 ,但实际上并不是同个东西。
1. 图像领域中的位图
a. 位图简介
位图,又称为点阵图像、像素图或栅格图像,是由像素(图片元素)的单个点组成。这些点可以进行不同的排列和染色以构成图样。
图像领域中的 位图 和 矢量图 是对立的概念。
位图的单位:像素(Pixel)
像素(Pixel):指可以表现亮度甚至色彩变化的一个点,是构成数字图像的最小单位。像素具有大小相同、明暗和颜色的变化。特点是有固定的位置和特定的颜色值。
位图有以下特点:
- 1.位图图像善于重现颜色的细微层次,能够制作出色彩和亮度变化丰富的图像;
- 2.文件庞大,不能随意缩放;
- 3.打印和输出的精度是有限的;
- 4.图形面积越大,文件的字节数越多;
- 5.文件的色彩越丰富,文件的字节数越多。
位图的文件类型很多,如:
1 | *.bmp、*.pcx、*.gif、*.jpg、*.tif |
b. 位图存储方式与计算
我们知道,每张图按大小来存储,即图像的长宽像素大小。如果一张图片的像素是 100100,则此图像在内存的存放是一个100100 的数组,每个数组的元素是 int 整型(整数占用 4 个 byte )。
需要补充一些知识:数组中每个元素中整型数字含四位信息:R-G-B-A。
- 1.R: 存放 Red 红色通道(占一个 byte 取值 0~255)
- 2.G: Green 绿色通道色(占一个 byte 取值 0~255 )
- 3.B: Blue 蓝色通道(占一个 byte 取值 0~255 )
- 4.A:Alpha 通道值,即该位置像素点的透明值(占一个 byte 取值 0~255)
其中 RGB 又是自然界三原色,通过 RGB 的组合可以将任何色彩表示出来。
我们举一个例子,假设有如下数组:
1 | {0xffff0000,0xffff0000,0xffff0000,0xffff0000}, |
表示这是一张 4*4 像素大小的全红色的图。一个像素在屏幕上显示出来非常小,当多个不同的像素按规律摆放在一起形成有行有列的数组的时候,我们就看到了图像。
一张图片(BitMap)占用的内存 = 图片长度 * 图片宽度 * 单位像素占用的字节数
单位像素基本上都是由 RGBA 四个元素组成,每个单元范围是 0~256 ,也就是 2^8 ,也就是 16 ^ 2,所以需要两个十六进制的来表示,
因为是 2^8 ,所以在存储计算上也就是需要 8个二进制bit, 也就是 1个字节,那么 RGBA 就是4个字节。
1 | 我们在定义颜色的时候就是使用 rgba(r,g,b,a) 四个维度来表示,而且每个像素值就是用十六位 00-ff 表示, |
2. 数据结构之位图(bitmap)
位图bitmap 是一种非常常用的结构,在索引,数据压缩等方面有广泛应用。
所谓的 bitmap 就是用一个 bit 位来标记某个元素对应的 value, 而 key 即是该元素。由于采用了 bit 为单位来存储数据,因此在存储空间方面,可以大大节省。
来看一个具体的例子,假设我们要对 0-7 内的 5 个元素 (4,7,2,5,3) 排序(这里假设这些元素没有重复)。那么我们就可以采用 bitmap 的方法来达到排序的目的。
二、主线程和UI绘制的关系
关于为什么进行UI绘制时必须保证在主线程这个问题,我们可能听到最多的解释是:
UIKit 线程不安全,如果加锁又会造成效率损失,所以苹果把UI相关的接口强行约束在主线程
这个回答应该是速成班教的,稍微了解后就发现上面这个说法不靠谱。
(一)Apple 是如何实现主线程检测UI调用代码的?
Main Thread Checker(后面简称MTC)简单来说就是一个适用于Swift和C语言的小工具。当必须在主线程执行的API在非主线程被调用的时候, MTC会报错并暂停程序执行。该类API包括
AppKit的接口、UIKit的接口和其他需要在主线程执行的API等。
MTC的原理官网也说的比较明白了。在App启动的时候,加载动态库——libMainThreadChecker.dylib,每个装了Xcode 9的人都能在/Applications/Xcode.app/Contents/Developer/usr/lib/目录下找到该动态库。这个动态库替换了所有应该在主线程调用的方法,替换后的方法会在函数执行之前先检查当前执行的线程是否是主线程,如果不是的话就报错。
Detect invalid use of AppKit, UIKit, and other APIs from a background thread.
也就是说哪些方法只能在主线程调用,实际上是运行Xcode时开启的一个 Main Thread Checker,MTC 并不是只约束了 UIKit,APPKit还有一些 APIs 也被约束了。
苹果使用 libMainThreadChecker.dylib 动态库对这些约束的方法进行替换,然后在调用阶段去检查是否在 主线程。
所以这里我们熟悉三件事:
- MTC 是如何实现的
- MTC 并不是只对UIKit进行了约束
- MTC 是可以在Xcode编译阶段关闭的
(二)什么是主线程?为什么不允许在子线程操作UI?
UIApplication在主线程所初始化的Runloop我们称为Main Runloop,它负责处理app存活期间的大部分事件,如用户交互等,它一直处于不断处理事件和休眠的循环之中,以确保能尽快的将用户事件传递给GPU进行渲染,使用户行为能够得到响应,画面之所以能够得到不断刷新也是因为Main Runloop在驱动着。
也就是说,并不是因为它叫主线程,所以它承载着UI相关的逻辑,而是因为 Application 启动时需要将交互事件放在一个线程里,所以这个线程叫做主线程,这个线程中的 threadMgr Runloop 称为 Main Runloop。
如果允许在子线程操作 UI,会因为UI不一致出现非常多的问题,我举个简单的例子:
1 | 游戏规则:屏幕出现图片时,点击图片获得胜利。 |
- 用户在没有屏幕没有出现图片时,点击了屏幕。
- 这时CPU时间分片切到子线程,渲染完毕后交给主线程,
- 然后主线程看到图片被渲染出来,结果判定成功
你可能说出现这个问题是因为 交互回调 只在主线程响应造成的,如果 用户的交互回调 可以跨线程同步,那么就会避免这个问题。
实际上:跨线程同步也不能避免这个问题,而且 交互回调 跨线程通信,从架构上是没法实现的事情,下面说一下原因。
(三)交互回调 为什么不能支持跨线程通信?
要回答这个问题,我们要先从最底层的渲染说起。
1. 渲染系统框架

- UIKit: 包含各种控件,负责对用户操作事件的响应,本身并不提供渲染的能力
- Core Animation: 负责所有视图的绘制、显示与动画效果
- OpenGL ES: 提供2D与3D渲染服务
- Core Graphics: 提供2D渲染服务
- Graphics Hardware: 指GPU
所以在iOS中,所有视图的现实与动画本质上是由 Core Animation 负责,而不是UIKit。
2. Core Animation Pipeline 流水线
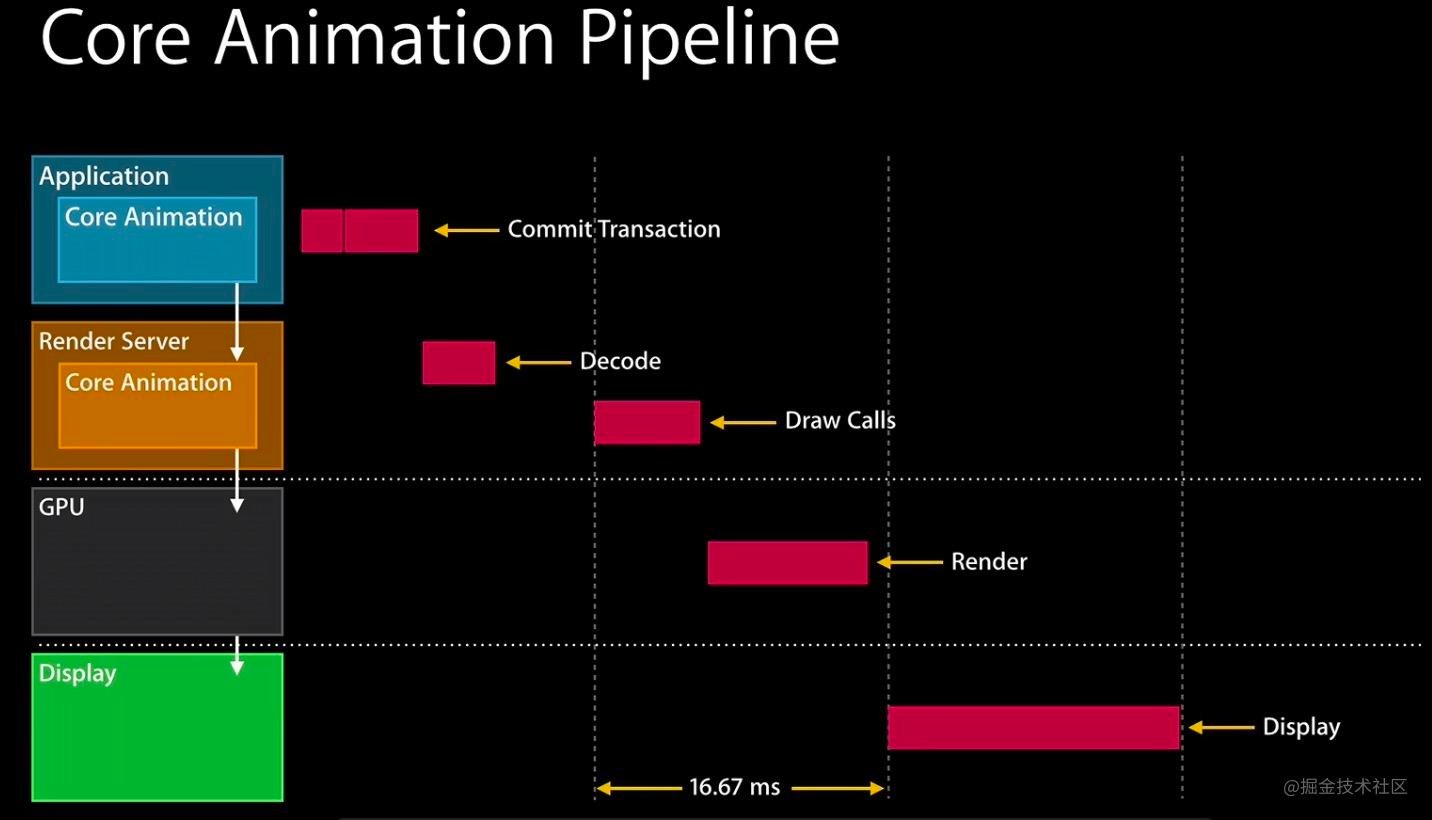
整个流水线一共有下面几个步骤:
- Handle Events:这个过程中会先处理点击事件,这个过程中有可能会需要改变页面的布局和界面层次。
- Commit Transaction:此时 app 会通过 CPU 处理显示内容的前置计算,比如布局计算、图片解码等任务,接下来会进行详细的讲解。之后将计算好的图层进行打包发给 Render Server。
- Decode:打包好的图层被传输到 Render Server 之后,首先会进行解码。注意完成解码之后需要等待下一个 RunLoop 才会执行下一步 Draw Calls。
- Draw Calls:解码完成后,Core Animation 会调用下层渲染框架(比如 OpenGL 或者 Metal)的方法进行绘制,进而调用到 GPU。
- Render:这一阶段主要由 GPU 进行渲染。
- Display:显示阶段,需要等 render 结束的下一个 RunLoop 触发显示。
Tips:Core Animation Pipeilne 和 Core Animation 使用没有关系,只是把上面这套流程叫做 Core Animation Pipeline 而已,Core Animation 只参与了上面的1-4环节。
- 1-2:高级语言,和布局相关
- 3-4:render server 完成高级语言到 bitmap 的转换
- 5:GPU 对 bitmap 进行并行计算,生成最终的 frameBuffer
- 6:显示器使用 VSync 机制,触发数模转换,展示图片
Core Animation 其实是类似 runloop 的角色,可以叫 animationMgr ,可以实现跨进程通信。
1) Commit Transaction 发生了什么
一般开发当中能影响到的就是 Handle Events 和 Commit Transaction 这两个阶段,这也是开发者接触最多的部分。
Handle Events 就是处理触摸事件,而 Commit Transaction 这部分中主要进行的是:Layout、Display、Prepare、Commit 等四个具体的操作。
####### Layout:构建视图
这个阶段主要处理视图的构建和布局,具体步骤包括:
- 调用重载的 layoutSubviews 方法
- 创建视图,并通过 addSubview 方法添加子视图
- 计算视图布局,即所有的 Layout Constraint
由于这个阶段是在 CPU 中进行,通常是 CPU 限制或者 IO 限制,所以我们应该尽量高效轻量地操作,减少这部分的时间,比如减少非必要的视图创建、简化布局计算、减少视图层级等。
Display:绘制视图
这个阶段主要是交给 Core Graphics 进行视图的绘制,注意不是真正的显示,而是得到前文所说的图元 primitives 数据:
1.根据上一阶段 Layout 的结果创建得到图元信息。
2.如果重写了 drawRect:方法,那么会调用重载的drawRect: 方法,在 drawRect: 方法中手动绘制得到 bitmap 数据,从而自定义视图的绘制。
注意正常情况下 Display 阶段只会得到图元 primitives 信息,而位图 bitmap 是在 GPU 中根据图元信息绘制得到的。但是如果重写了 drawRect:方法,这个方法会直接调用 Core Graphics 绘制方法得到 bitmap 数据,同时系统会额外申请一块内存,用于暂存绘制好的 bitmap。
由于重写了 drawRect: 方法,导致绘制过程从 GPU 转移到了 CPU,这就导致了一定的效率损失。与此同时,这个过程会额外使用 CPU 和内存,因此需要高效绘制,否则容易造成 CPU 卡顿或者内存爆炸。
Prepare:Core Animation 额外的工作
这一步主要是:图片解码和转换
Commit:打包并发送
这一步主要是:图层打包并发送到 Render Server。
注意 commit 操作是依赖图层树递归执行的,所以如果图层树过于复杂,commit 的开销就会很大。这也是我们希望减少视图层级,从而降低图层树复杂度的原因。
2)Render Server
负责渲染工作,会解析上一步Commit Transaction中提交的信息并反序列化成渲染树(render tree),随后根据layer的各种属性生成绘制指令,并在下一次VSync信号到来时调用OpenGL进行渲染。
App使用Core Grapics、Core Animation、Core Image等框架来绘制可视化内容。这些框架需要通过Metal(iOS12之前是通过OpenGL ES)来调用GPU进行绘制,最后将绘制好的内容显示在屏幕上。
3)GPU
GPU会等待显示器的VSync信号发出后才进行OpenGL渲染管线,将3D几何数据转化成2D的像素图像和光栅处理,随后进行新的一帧的渲染,并将其输出到缓冲区。
4)Dispaly
从缓冲区中取出画面,并输出到屏幕上。
3. render server 是什么?
我们看到,在承担渲染工作的并不是 App 的进程,而是一个叫 render server 的进程。
Render Server 通常是 OpenGL 或者是 Metal。以 OpenGL 为例,那么上图主要是 GPU 中执行的操作,具体主要包括:
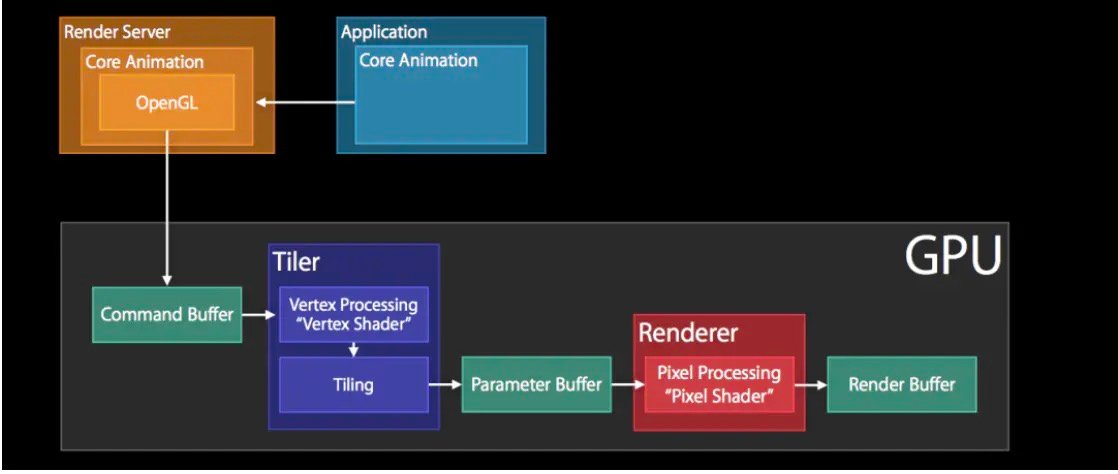
- 1.GPU 收到 Command Buffer,包含图元 primitives 信息
- 2.Tiler 开始工作:先通过顶点着色器 Vertex Shader 对顶点进行处理,更新图元信息
- 3.平铺过程:平铺生成 tile bucket 的几何图形,这一步会将图元信息转化为像素,之后将结果写入 Parameter Buffer 中
- 4.Tiler 更新完所有的图元信息,或者 Parameter Buffer 已满,则会开始下一步
- 5.Renderer 工作:将像素信息进行处理得到 bitmap,之后存入 Render Buffer
- 6.Render Buffer 中存储有渲染好的 bitmap,供之后的 Display 操作使用
4. 结论
前面提到Core Animation Pipeline是以流水线的形式工作的,在理想的状况下我们希望它能够在1/60s内完成图层树的准备工作并提交给渲染进程,而渲染进程在下一次VSync信号到来的时候提交给GPU进行渲染,并在1/60s内完成渲染,这样就不会产生任何的卡顿。
但是由于我们使用了我们的魔法UIKit,所以我们在许多后台线程进行了UI操作,在runloop的结尾准备进行渲染的时候,不同线程提交了不同的渲染信息,于是我们就拥有了更多的绘制事务,这个时候Core Animation Pipeline会不断将信息提交,让GPU进行渲染,由于绘制事件的不同步导致了GPU渲染的不同步,可能在上一帧是需要渲染一个label消失的画面,下一帧却又需要渲染这个label改变了文字,最终导致的是界面的不同步。
Tips:也就是说,提供给GPU执行渲染任务的工作的接口一定只能是一个,如果是多个接口同时陆续提交了不同的渲染任务,那就很容易出现 VSync 到来之前没有合成完毕的情况:比如快合成完毕的时候,又有子线程提交了一个commit。
那我们还能不能实现异步子线程渲染呢? 还是有方法的,只是并不是通过修改MTC逻辑来做的,YYAsyncLayer、AsyncDisplayKit都是优秀的异步绘制框架,我们在第三部分会进行阐述。
三、绘制图像过程中CPU和GPU的分工(垂直同步信号、二级缓存等)
在大学里学习微机时,我们基本上只研究到了 8086CPU微机架构,没有把 GPU 加入到分析的流程中,我们在这里描述一下 CPU、GPU、显示器 一起合作运作的流程。
(一)CPU 和 GPU 工作分工
1. 总流程
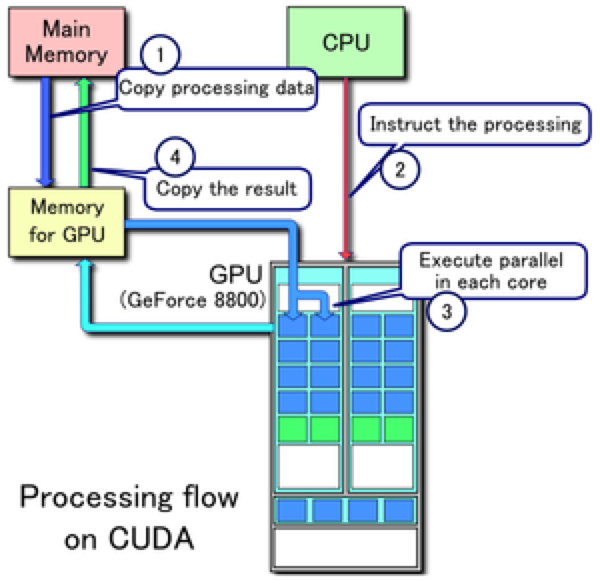
下图所示为 CPU-GPU 异构系统的工作流,当 CPU 遇到图像处理的需求时,会调用 GPU 进行处理,主要流程可以分为以下四步:
- 将主存的处理数据复制到显存中
- CPU 指令驱动 GPU(CPU 将 drawCall 指令存入 指令寄存器,GPU完成一次 drawCall 指令后去 指令寄存器 取下一次命令)
- GPU 中的每个运算单元并行处理
- GPU 将显存结果传回主存
2. 具体架构
至此,我们大致了解了 GPU 的工作原理和内部结构,那么实际应用中 CPU 和 GPU 又是如何协同工作的呢?
下图所示为两种常见的 CPU-GPU 异构架构。
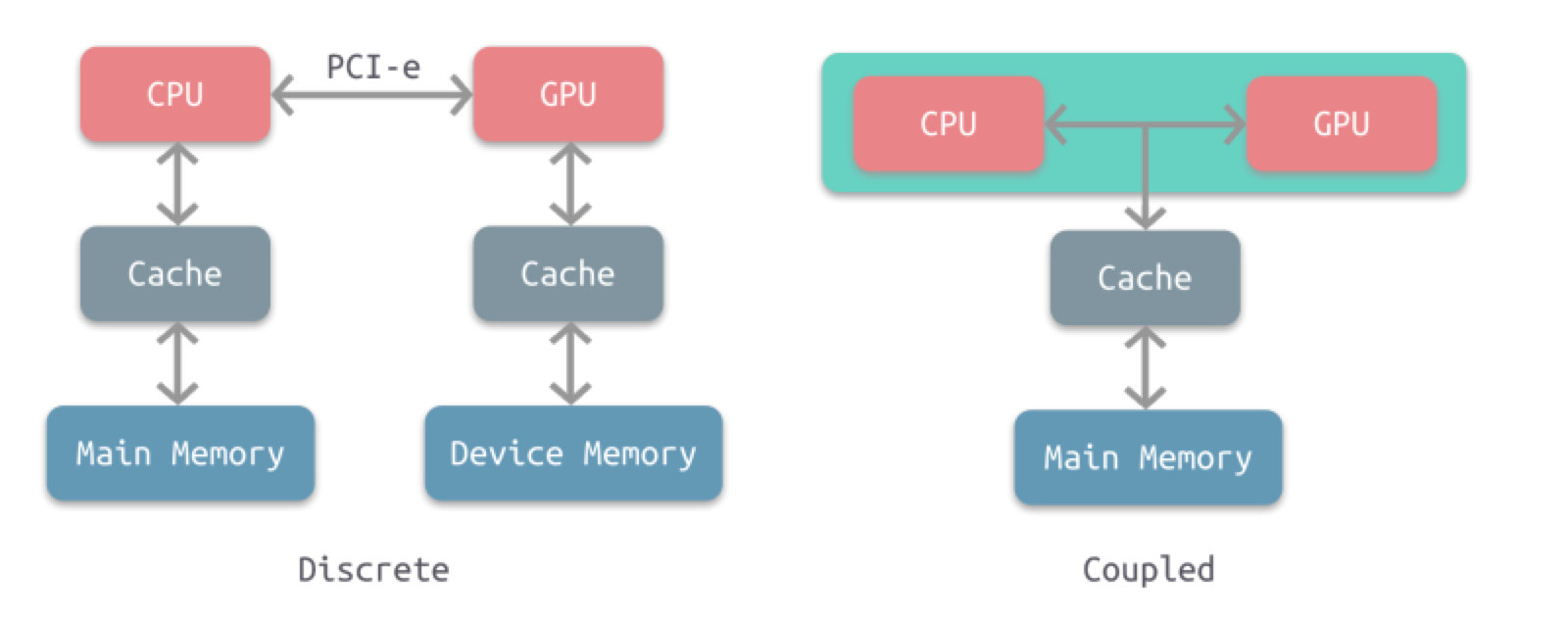
左图是分离式的结构,CPU 和 GPU 拥有各自的存储系统,两者通过 PCI-e 总线进行连接。这种结构的缺点在于 PCI-e 相对于两者具有低带宽和高延迟,数据的传输成了其中的性能瓶颈。目前使用非常广泛,如PC、智能手机等。
右图是耦合式的结构,CPU 和 GPU 共享内存和缓存。AMD 的 APU 采用的就是这种结构,目前主要使用在游戏主机中,如 PS4。
注意,目前很多 SoC 都是集成了CPU 和 GPU,事实上这仅仅是在物理上进行了集成,并不意味着它们使用的就是耦合式结构,大多数采用的还是分离式结构。耦合式结构是在系统上进行了集成。
在存储管理方面,分离式结构中 CPU 和 GPU 各自拥有独立的内存,两者共享一套虚拟地址空间,必要时会进行内存拷贝。对于耦合式结构,GPU 没有独立的内存,与 GPU 共享系统内存,由 MMU 进行存储管理。
图形应用程序调用 OpenGL 或 Direct3D API 功能,将 GPU 作为协处理器使用。API 通过面向特殊 GPU 优化的图形设备驱动向 GPU 发送命令、程序、数据。
(二)显示器的运作原理
1. 垂直同步信号
介绍屏幕图像显示的原理,需要先从 CRT 显示器原理说起,如下图所示。CRT 的电子枪从上到下逐行扫描,扫描完成后显示器就呈现一帧画面。然后电子枪回到初始位置进行下一次扫描。为了同步显示器的显示过程和系统的视频控制器,显示器会用硬件时钟产生一系列的定时信号。当电子枪换行进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync;而当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(vertical synchronization),简称 VSync。显示器通常以固定频率进行刷新,这个刷新率就是 VSync 信号产生的频率。虽然现在的显示器基本都是液晶显示屏了,但其原理基本一致。
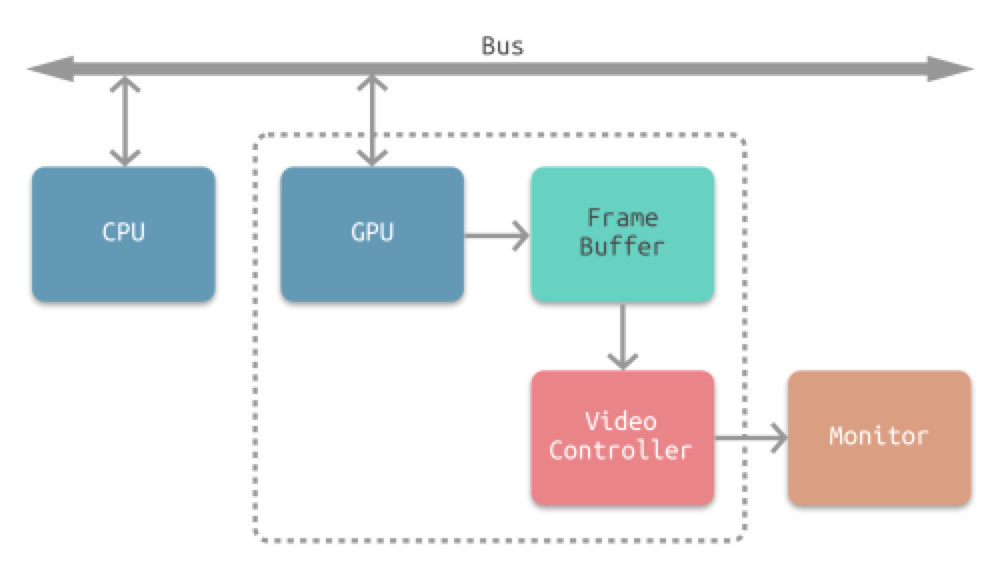
下图所示为常见的 CPU、GPU、显示器工作方式。CPU 计算好显示内容提交至 GPU,GPU 渲染完成后将渲染结果存入帧缓冲区,视频控制器会按照 VSync 信号逐帧读取帧缓冲区的数据,经过数据转换后最终由显示器进行显示。
Tips:帧缓冲区(显存):是由像素组成的二维数组,每一个存储单元对应屏幕上的一个像素,整个帧缓冲对应一帧图像即当前屏幕画面。帧缓冲通常包括:颜色缓冲,深度缓冲,模板缓冲和累积缓冲。这些缓冲区可能是在一块内存区域,也可能单独分开,看硬件。
2. 帧缓冲区和二级缓存
最简单的情况下,帧缓冲区只有一个。此时,帧缓冲区的读取和刷新都都会有比较大的效率问题。为了解决效率问题,GPU 通常会引入两个缓冲区,即 双缓冲机制。在这种情况下,GPU 会预先渲染一帧放入一个缓冲区中,用于视频控制器的读取。当下一帧渲染完毕后,GPU 会直接把视频控制器的指针指向第二个缓冲器。
那么目前主流的移动设备是什么情况呢?从网上查到的资料可以知道,iOS 设备会始终使用双缓存,并开启垂直同步。而安卓设备直到 4.1 版本,Google 才开始引入这种机制,目前安卓系统是三缓存+垂直同步。
解决屏幕撕裂、提高显示效率的一个策略就是使用垂直同步信号 Vsync 与双缓冲机制 Double Buffering。根据苹果的官方文档描述,iOS 设备会始终使用 Vsync + Double Buffering 的策略。
垂直同步信号(vertical synchronisation,Vsync)相当于给帧缓冲器加锁:当电子束完成一帧的扫描,将要从头开始扫描时,就会发出一个垂直同步信号。只有当视频控制器接收到 Vsync 之后,才会将帧缓冲器中的位图更新为下一帧,这样就能保证每次显示的都是同一帧的画面,因而避免了屏幕撕裂。
但是这种情况下,视频控制器在接受到 Vsync 之后,就要将下一帧的位图传入,这意味着整个 CPU+GPU 的渲染流程都要在一瞬间完成,这是明显不现实的。所以双缓冲机制会增加一个新的备用缓冲器(back buffer)。渲染结果会预先保存在 back buffer 中,在接收到 Vsync 信号的时候,视频控制器会将 back buffer 中的内容置换到 frame buffer 中,此时就能保证置换操作几乎在一瞬间完成(实际上是交换了内存地址)。
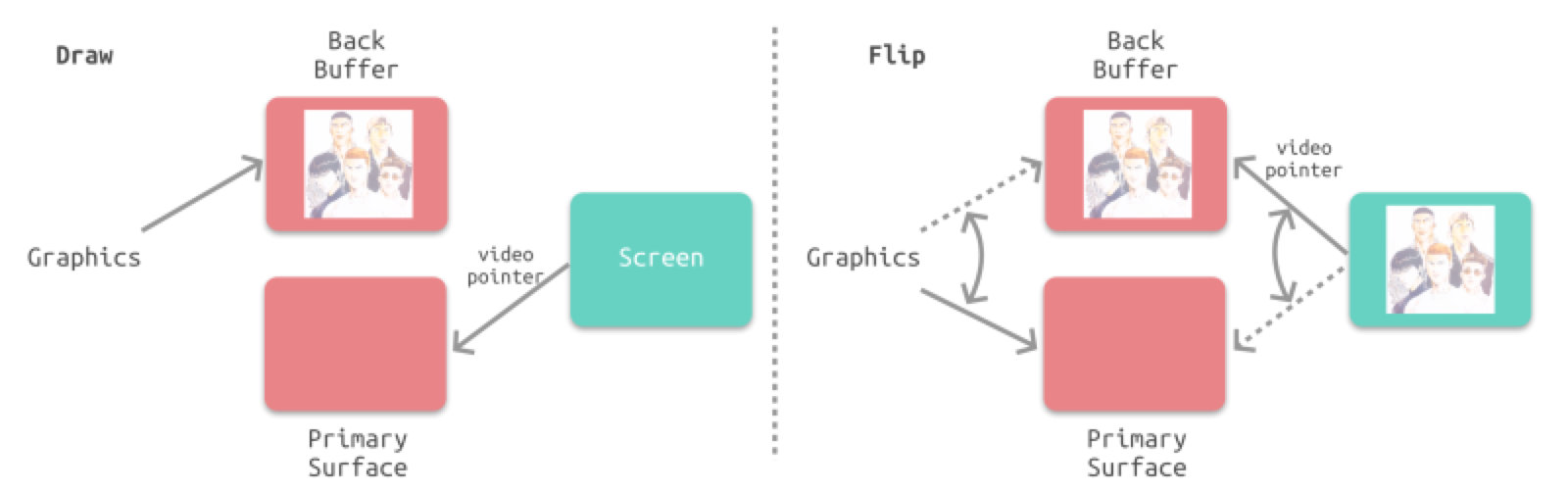
启用 Vsync 信号以及双缓冲机制之后,能够解决屏幕撕裂的问题,但是会引入新的问题:掉帧。如果在接收到 Vsync 之时 CPU 和 GPU 还没有渲染好新的位图,视频控制器就不会去替换 frame buffer 中的位图。这时屏幕就会重新扫描呈现出上一帧一模一样的画面。相当于两个周期显示了同样的画面,这就是所谓掉帧的情况。
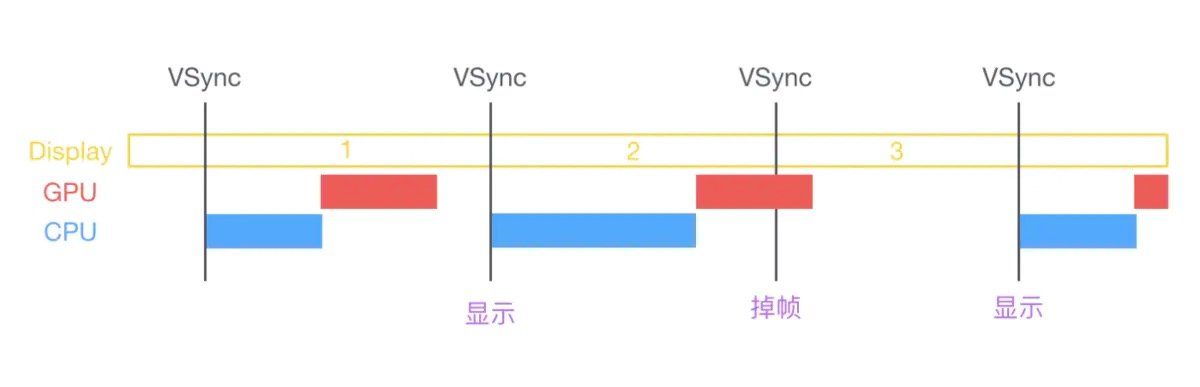
3. 三级缓存
事实上上述策略还有优化空间。我们注意到在发生掉帧的时候,CPU 和 GPU 有一段时间处于闲置状态:当 A 的内容正在被扫描显示在屏幕上,而 B 的内容已经被渲染好,此时 CPU 和 GPU 就处于闲置状态。那么如果我们增加一个帧缓冲器,就可以利用这段时间进行下一步的渲染,并将渲染结果暂存于新增的帧缓冲器中。

为了解决这个问题,GPU 通常有一个机制叫做垂直同步(简写也是 V-Sync),当开启垂直同步后,GPU 会等待显示器的 VSync 信号发出后,才进行新的一帧渲染和缓冲区更新。这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟。
4. 卡顿的本质
手机使用卡顿的直接原因,就是掉帧。前文也说过,屏幕刷新频率必须要足够高才能流畅。对于 iPhone 手机来说,屏幕最大的刷新频率是 60 FPS,一般只要保证 50 FPS 就已经是较好的体验了。但是如果掉帧过多,导致刷新频率过低,就会造成不流畅的使用体验。
这样看来,可以大概总结一下
屏幕卡顿的根本原因:CPU 和 GPU 渲染流水线耗时过长,导致掉帧。
- Vsync 与双缓冲的意义:强制同步屏幕刷新,以掉帧为代价解决屏幕撕裂问题。
- 三缓冲的意义:合理使用 CPU、GPU 渲染性能,减少掉帧次数。
(三)GPU 为什么适用于高并发图形计算?
我们要明白的是:图形的计算本质上是一块区域(纹理)的二进制计算,单个像素的计算难度不大,但图像计算难就难在像素过大时,出现了指数倍数增长的这种简单计算。
所以出现了 GPU 专门高并发处理这种简单的纹理合成计算。
1. CPU存储系统
早期的 GPU,不同的着色器对应有着不同的硬件单元。如今,GPU 流水线则使用一个统一的硬件来运行所有的着色器。此外,nVidia 还提出了 CUDA(Compute Unified Device Architecture) 编程模型,可以允许开发者通过编写 C 代码来访问 GPU 中所有的处理器核,从而深度挖掘 GPU 的并行计算能力。
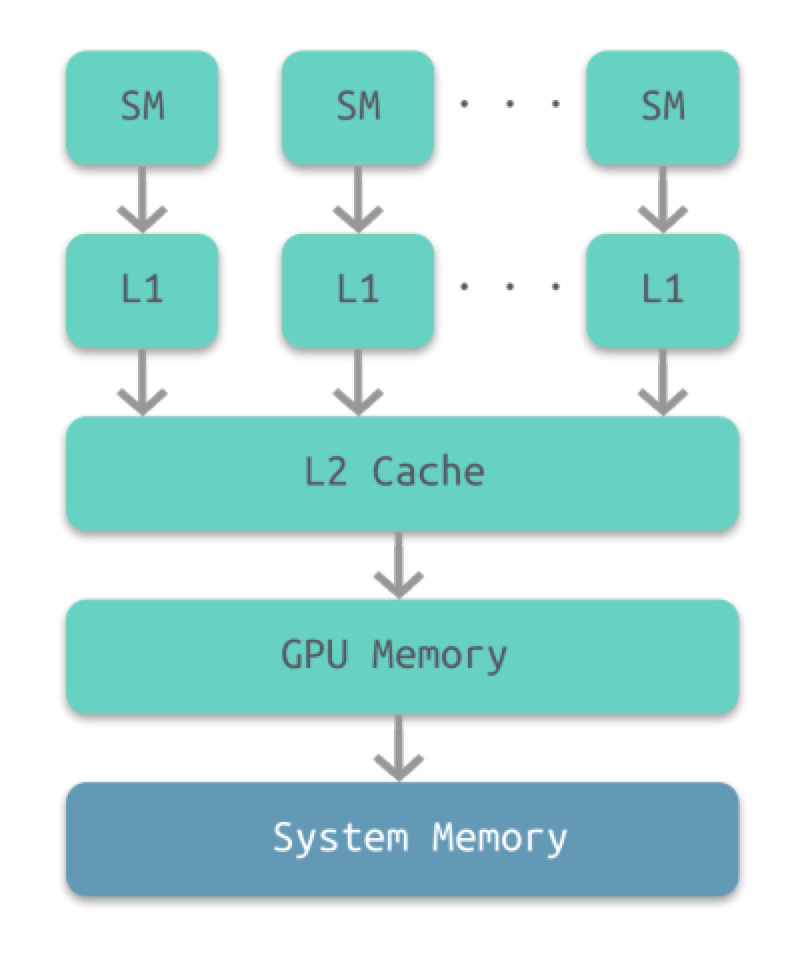
下图所示为 GPU 内部的层级结构。最底层是计算机的系统内存,其次是 GPU 的内部存储,然后依次是两级 cache:L2 和 L1,每个 L1 cache 连接至一个 流处理器(SM,stream processor)。
- SM L1 Cache 的存储容量大约为 16 至 64KB。
- GPU L2 Cache 的存储容量大约为几百 KB。
- GPU 的内存最大为 12GB。
- GPU 上的各级存储系统与对应层级的计算机存储系统相比要小不少。
此外,GPU 内存并不具有一致性,也就意味着并不支持并发读取和并发写入。
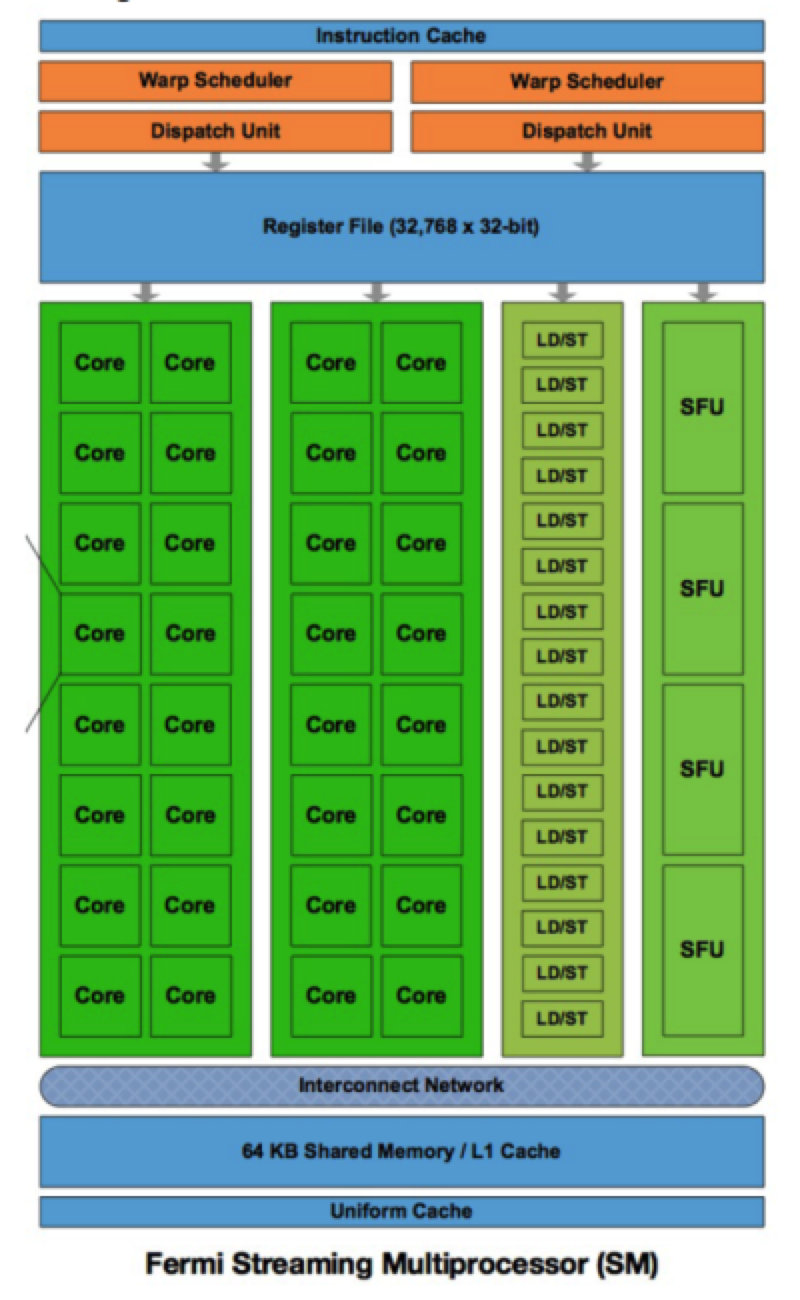
2. GPU 流处理器
下图所示为 GPU 中每个流处理器的内部结构示意图。每个流处理器集成了一个 L1 Cache。顶部是处理器核共享的寄存器堆。
Tips:

iPhone 12 Pro 用到了 6核CPU,4核GPU,二级缓存。
(四)什么是光栅化
我们看到 GPU 工作时有一个词是 光栅化 ,这个词我们听的频率也很高,那么什么是光栅化呢?
假定屏幕分辨率为1920×1080,在二维屏幕渲染(光栅化)时,内存中frame buffer只保存着1920×1080个屏幕点的颜色,然后一个一个的画到屏幕上。(它的实现方式是以一个1920×1080长的一维数组储存每个顶点的RGB颜色,然后遍历数组画出来)。
什么X, Y, Z,什么alpha之类的frame buffer都没有的,在frame buffer里只有3个值:R, G, B。
X, Y, Z, alpha等等属性要在另外的地方存储。
光栅化,就是计算出1920×1080这么长的RGB数组中,每一个RGB的值。
四、图像绘制原理
(一)离屏渲染
1. 离屏渲染具体过程
根据前文,简化来看,通常的渲染流程是这样的:
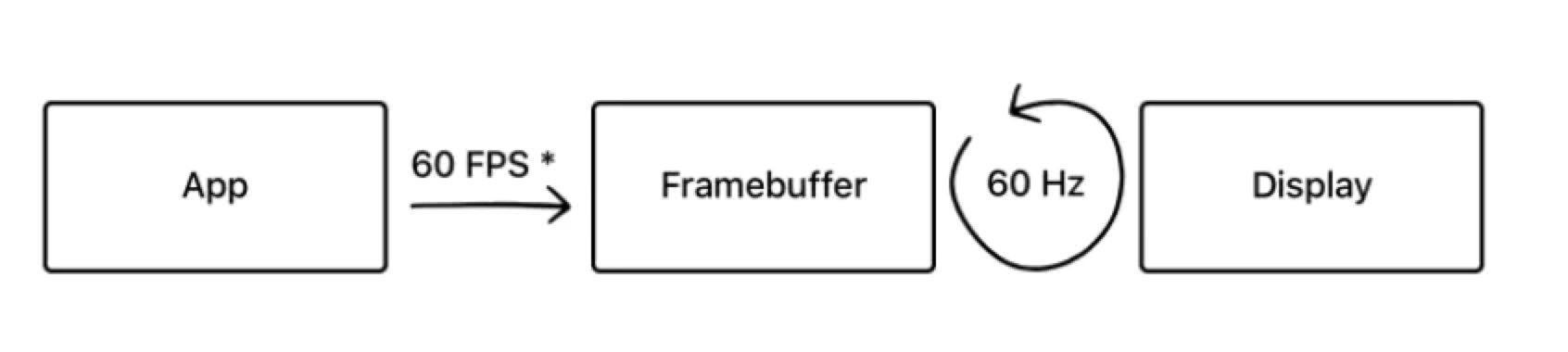
App 通过 CPU 和 GPU 的合作,不停地将内容渲染完成放入 Framebuffer 帧缓冲器中,而显示屏幕不断地从 Framebuffer 中获取内容,显示实时的内容。
而离屏渲染的流程是这样的:

与普通情况下 GPU 直接将渲染好的内容放入 Framebuffer 中不同,需要先额外创建离屏渲染缓冲区 Offscreen Buffer,将提前渲染好的内容放入其中,等到合适的时机再将 Offscreen Buffer 中的内容进一步叠加、渲染,完成后将结果切换到 Framebuffer 中。
2. 离屏渲染的效率问题
从上面的流程来看,离屏渲染时由于 App 需要提前对部分内容进行额外的渲染并保存到 Offscreen Buffer,以及需要在必要时刻对 Offscreen Buffer 和 Framebuffer 进行内容切换,所以会需要更长的处理时间(实际上这两步关于 buffer 的切换代价都非常大)。
并且 Offscreen Buffer 本身就需要额外的空间,大量的离屏渲染可能早能内存的过大压力。与此同时,Offscreen Buffer 的总大小也有限,不能超过屏幕总像素的 2.5 倍。
可见离屏渲染的开销非常大,一旦需要离屏渲染的内容过多,很容易造成掉帧的问题。所以大部分情况下,我们都应该尽量避免离屏渲染。
所以要明白的是,离屏渲染会导致两个问题:
- 内存开销过大:开辟了新的缓存 offscreen buffer 存离屏渲染的数据
- 渲染时间变长:offscreen buffer 和 framebuffer 进行 上下文切换时,代价非常大
离屏渲染是发生在GPU层的,重写 drawRect: 是将 GPU 的工作前置到了 CPU,不算是非常标准的离屏渲染。
3. 如何检测屏幕的离屏渲染
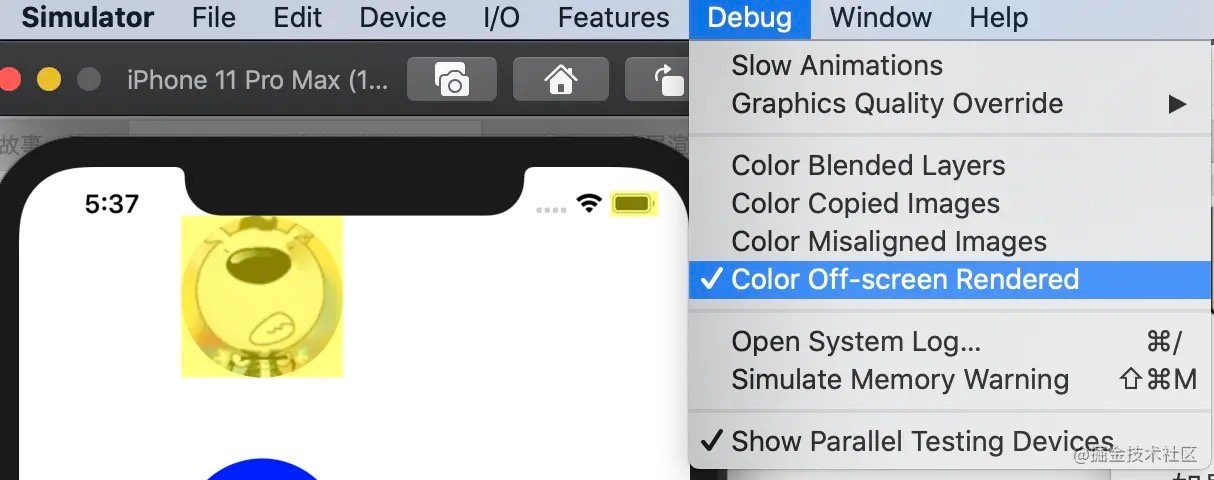
模拟器 可以通过设置 Debug -> Color Off-screen Rendered 来打开离屏渲染检测
真机 则通过设置 Debug -> View Debugging -> Rendering -> Color Off-screen Rendered 来打开离屏渲染检测
具体情况如上图那样, 图中的颜色呈现 黄色 的区域就是触发了 离屏渲染 的区域