-
环境问题
- mac上有多个python时,更新库使用这个方法
python3.10 -m pip install gradio
- 不要尝试修改mac上python的默认版本号!
这是蠢b行为!

前言
在客户端埋头苦干跨端、SwiftUI的同时,我们也抽出点时间逐步深入大模型,看看有没有什么好玩的技术方案和商业模式。
大模型的火爆程度诸位有目共睹,本篇就不多做赘述。
本篇描述重点在于收集市场现有成熟产品的底层架构,了解从大模型到落地产品的技术方案,以及从客户端角度比较关心的api和收费问题。
一、现有大模型产品分类和商业模型
根据我在aigc前沿的观察,以及和业内人士的沟通,大模型产品大概可以分为这么三类:
- chatGPT套壳
- LLaMA/chatGLM 魔改赋能(重点)
- github开源玩具
(一)chatGPT套壳
这种套壳App众多,竞争可谓红海,这个产品领域大家都在卷什么呢?
1. 基础功能赋能
(1)连网功能
熟悉chatGPT的同学应该知道chatGPT已经出了连网的plugin,那用chatGPT套壳的软件为什么还要支持连网功能呢?
原因很简单,因为chatGPT4 连网plugin 的费用比较高,所以这些应用基于 chatGPT3.5 + 自己封装的一层连网中间层,降低了连网的成本。
(2)中间层存储
熟悉chatGPT的同学应该听说过chatGPT session错乱的问题(A和chatGPT的聊天记录会串到B和chatGPT的聊天记录里),虽然这个bug已经修复了,
但session在chatGPT这种网站存储总是感觉不安全,如果你有一个session是用chatGPT训练的虚拟女友,这个session丢失问题就非常大了!
所以套壳App又提供了一层本地存储和后台存储服务,加上chatGPT本身的存储逻辑,相当于一份会话session存储到了3个地方,再也不担心丢失session了。
- 预训练prompt
如果你是chatGPT重度用户,你在和他对话前估计会先让他明确身份,比如如果我在咨询它iOS的问题时,我会先说一句:
“你好,我是iOS开发,代码使用OC语言开发,你接下来回复我的所有问题请从iOS开发的角度回答,代码使用OC格式。”
这样我咨询的iOS问题,chatGPT就不会用Swift语言回答了。
基于类似的需求,”虚拟女友 prompt”、”周报 prompt”、”解梦 prompt”的预训练功能就诞生了。
- 成本众包
这点和技术无关,但我觉得十分有意思,也聊一下。
你有没有想过一个问题,使用 chatGPT套壳 的app,会怎么向它的用户收费呢?
如果你知道chatGPT是使用token来计算费用的,那么你距离猜出它的商业模式就不远了:
套壳App在平台上再发行一种积分,这种积分用于和chatGPT token消耗绑定。
这样做有什么好处呢?
我用一个大家购买VPN服务的场景举例,如果你购买过VPN,假设一年100块,你可能真正使用到的VPN流量只有30%左右,那么剩下的70%是不是就浪费了?
但如果你对朋友说:”我来购买一年的VPN,花费100元。你们三个来我这里使用VPN,按使用流量给,每年大致消耗50元就行”,这样你最终还会倒赚50块。
说白了,这在商业上属于一种成本众包,服务商和用户双赢。
(二)LLaMA/chatGLM 魔改赋能
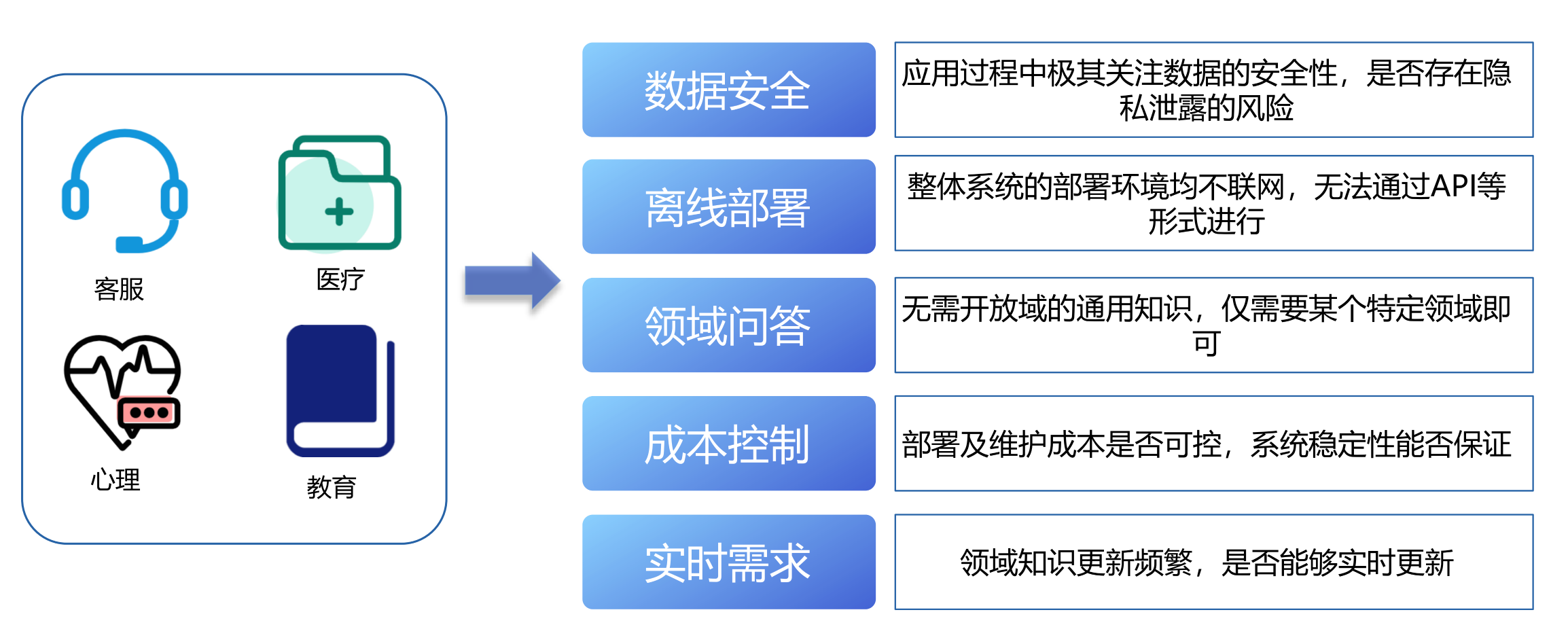
因为数据安全等原因,目前创业类公司使用类chatGPT功能时,基本都是基于 LLaMA/chatGLM 开源框架进行二次定制的,这个技术选型不仅能支持垂直领域知识喂养,
还是真正实现边际成本为零的技术方案,也是我们下面要描述的重点。
(三)github开源玩具
类似chatPDF这类开源项目,可能是因为只是简单的集成现有模型,在集成者对模型机理不够了解的背景下,随着模型的滞后,也慢慢淡出生产力行列。
二、LLaMA/chatGLM
(一)什么是 LLaMA/chatGLM ?
LLaMA 和 chatGLM 都是开源的大语言模型,前者是 Meta 研究开源,后者是清华大学开源。
两者定位不同,Meta发布LLaMA初衷就是硬刚chatGPT,立志于通用大模型。
而chatGLM发布之初,清华大学研究院已经声明chatGLM不尝试在「通用领域」立足,而是做「垂直领域」。
(二)本地部署 chatGLM 效果如何?
M1部署chatGLM的流程可以Google,网上有很多,M1芯片完全可以运行,只是配置环境有些复杂。
正如上面所说的,chatGLM 和 chatGPT 对比,在coding、英语理解等领域基本处于完败的局面。
但当我喂养给 chatGLM 我私有的中文博客数据时,chatGLM 的表现就会比chatGPT好很多。
(三)如何迭代 chatGLM 达到更好效果?
1. 模型迭代
chatGLM 现在有不同大小的模型,可以单卡部署的6B模型,和内测的大模型。
所以提升 chatGLM 效果最直接的办法肯定是使用更多参数的 chatGLM ,前提是机器hold得住。
2. 知识喂养
上面有说到”知识喂养”,那具体是怎么”喂养”的呢? 是一句一句话教给chatGLM吗?那样效率就太低了。
这里介绍一个工具 LangChain ,LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,
可简化创建由大型语言模型 (LLM)和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
可以直接把你要喂养 chatGLM 的数据通过 langChain 训练给模型。
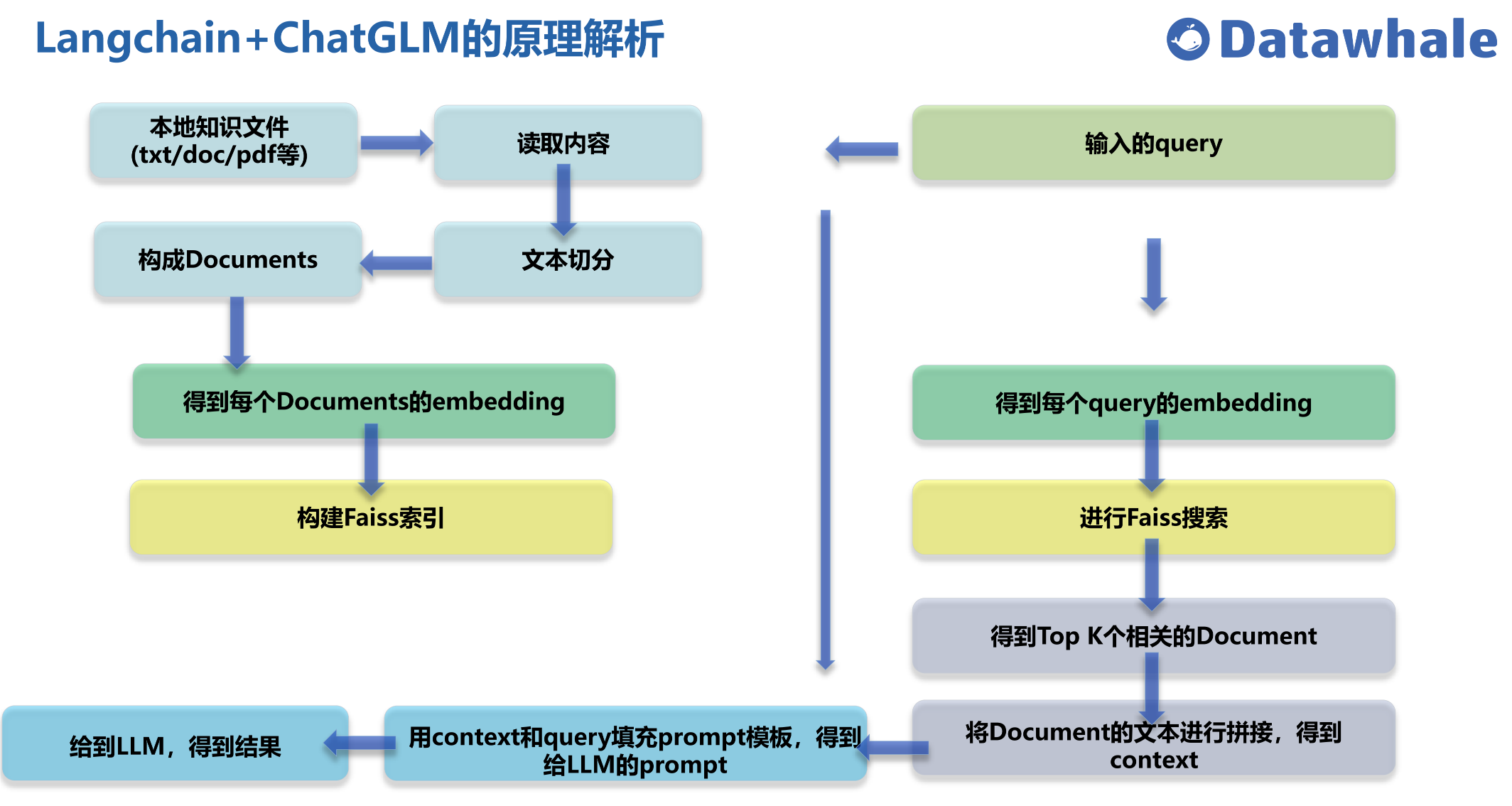
这里推荐一个github项目,直接将langchain和chatGLM两个项目进行了集成,
经过我自己的测试,这个项目部署起来比chatGLM单部署更简单。
(四)云服务器部署 chatGLM 可行吗?
既然说到了本地部署模型,作为客户端开发的大家可能已经想到了,本地部署 => 上云 => 生成类chatGPT的服务,这个逻辑可行吗?
答案是:YES。将 chatGLM 部署到你的云服务器后,执行项目中的 python api.py 脚本,就会利用 fastapi 生成相应的api,
这样你就可以拥有一个自己的免费的chatBot啦,据我所知业内很多创业公司都在这么做,所以如果你想这么做,就大胆做吧!